What is Data Science?
Defining the massively popular field in computer science and statistics
Hi, I’m Matt and I’m a data scientist.
But what is data science anyway?
There are a number of formal definitions out there on data science, but I think at its core data science is the ongoing disciplined and scientific approach to the study and application of data to achieve a meaningful goal using applied computer processing.
This is an intentionally broad definition, but I believe it encompasses the scope and value of data science without restricting the specific implementation details.
Let’s look at each part of this and get more of a sense of what data science actually involves.
This content is also available in video form on YouTube
Ongoing Disciplined and Scientific Approach
In data science there is a very real possibility that we can make a mistake, allow bias to enter into a machine learning solution, or otherwise corrupt the result of an experiment. Additionally, data science solutions can be employed in areas that can actively harm others if they wind up being inaccurate or biased. For example, loan evaluation routines or medical tests must be accurate, reliable, and ethical.
As a result, everything we do must be done with care and deliberation, from the selection of data to the inclusion of columns in the data set, to the machine learning routines we select, to how we evaluate the performance of those routines.
Experiments must be tracked and measured in a consistent way and we must take care in evaluating false positives as well as false negatives in classification routines and various measurements of error and distance for regression and clustering routines.
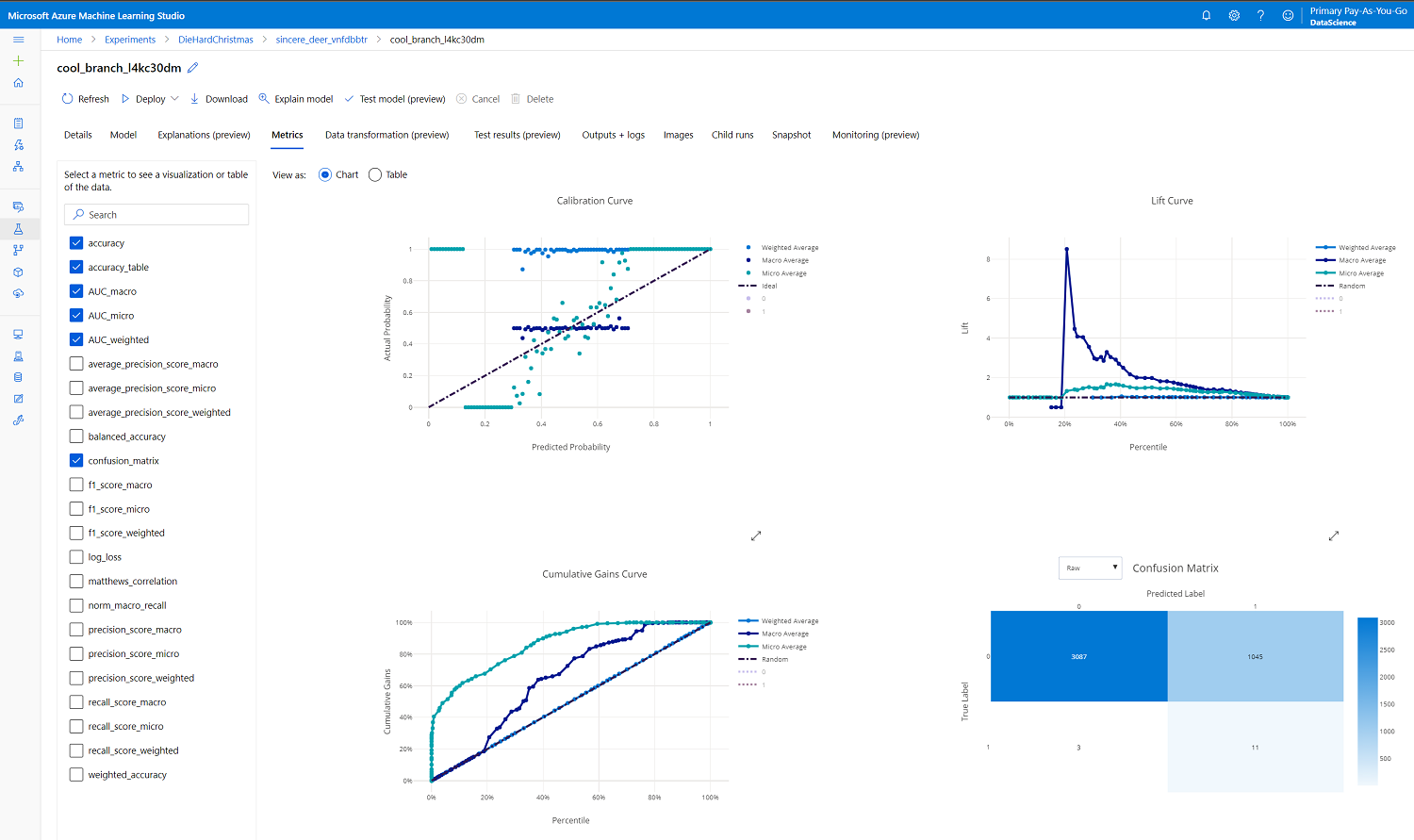
Sample metrics displayed from a classification run in Azure Machine Learning Studio
I also use the word ongoing in this portion of our definition. This is intentional because data science isn’t a one-time thing, but rather something that must be done regularly. Established machine learning pipelines must be monitored to detect data drift and any emergence of bias. Even one-off experiments can be revisited later to see if things have changed significantly with new data or shifts in technologies and society.
Study and Application of Data
Data science, unsurprisingly, involves data. Note here that I don’t explicitly say big data (which is the subject of a future article), but rather data of any scale and size.
This data may be processed as part of one-off experiments that are not repeated or via an automated pipeline that looks at incoming data in real-time or periodic batches, depending on the needs of your organization.
Studying data can involve statistical techniques, exploratory data analysis, and data visualization. However, these areas are traditionally more of the focus of a data analyst vs a data scientist, though they do have value to help understand potential relationships and correlations in data that can then be incorporated into a machine learning model.
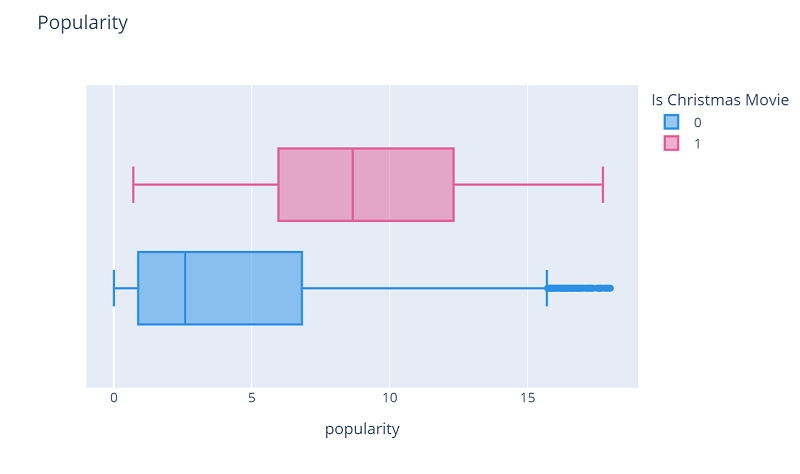
Sample box plot looking at the distribution of Christmas movies vs non-Christmas movies in a data set
Achieve a Meaningful Goal
While data science can be a lot of fun, the key point of data science is to provide some form of meaningful benefit to an organization or individual.
That means that our data science experiments and pipelines must be able to deliver reliable and trustworthy results that have value to an organization. If an organization does not trust the reliability or accuracy of its experiments, their value is significantly diminished and their ability to achieve the original goal is significantly limited.
However, if a data science experiment is reliable, accurate, and effective at achieving its original goal, it can transform the capabilities of a business by opening up solutions to problems that would be unsolvable or less effective using traditional programming or decision-making techniques.
Using Applied Computer Processing
Finally, data science involves the application of applied computer processing. Note that this statement doesn’t mention neural nets, linear regression algorithms, K Nearest Neighbor, decision trees, neural nets, or even the broader category of machine learning.
Certainly these things are all a part of data science, but data science doesn’t require the use of one of these routines to be considered data science. Instead, data science is focused on applying whatever algorithms and routines produce the best result for the organization and its stakeholders.
I also explicitly mention computer processing here because data science routines are accomplished by computers and often involve a massive amount of processing power to achieve the number of calculations needed to train and evaluate machine learning models.
In fact, very large machine learning tasks can necessitate clusters of computers and rely on the GPUs on graphics cards in order to perform the massive number of parallel calculations required for advanced scenarios and large data sets.
Conclusion
Now we reach the end and I’ll repeat my definition:
Data Science is the ongoing disciplined and scientific approach to the study and application of data to achieve a meaningful goal using applied computer processing
Do you agree? Is my definition too high-level? Did I miss something important? Let me know!

