
Applying Computer Vision to Winter Wonderlands
Making holiday photos accessible for all with the Azure AI Vision v4 API
This article is my entry as part of Festive Tech Calendar 2023. Visit FestiveTechCalendar.com more articles in the series by other authors.
In this article I’ll walk you through using C# to work with the new v4 Image Analysis API Microsoft offers with Azure AI Vision.
Like the v3.2 API that came before it, the v4 computer vision API offers AI as a service capabilities to extract information from images on your hard drive or accessible over the internet. However, the analysis experience is even better with the v4 API and offers some interesting new capabilities including dense captioning, people detection, and background removal.
Let’s see how the computer vision capabilities can help analyze some pictures of winter wonderlands.
Note: Special thanks to those who sent me photos for this article, including those I couldn’t fit in. Special thanks go out to Sergio, Claudio Bernasconi, Peter O’Hanlon, Kit Eason, Pete Gallagher, and Sahed Chowdhuri
Connecting to Azure Resources
First, this article assumes you have either an Azure AI Services resource or an Azure AI Vision resource. Either resource will work, but you’ll need the endpoint and one of the two keys for the resource in order to make calls from your C# code.
Next, you’ll need to install the Azure.AI.Vision.ImageAnalysis NuGet package. You may need to include pre-release versions of the API in order for this to install properly depending on when you follow along with this article.
After that, add the following using statements to a C# file:
using Azure;
using Azure.AI.Vision.ImageAnalysis;
using Azure.AI.Vision.Common;
Next we’ll need to authenticate with Azure. We do this by instantiating a VisionServiceOptions object pointing to our endpoint and using our credentials:
// Replace these with your credentials from the Keys and Endpoint blade in Azure
// Reminder: do not check these values into source control!
string endpoint = "FindThisOnYourAzureResource";
string key = "FindThisOnYourAzureResource";
AzureKeyCredential credential = new(key);
VisionServiceOptions serviceOptions = new(endpoint, credential);
This VisionServiceOptions object will be handy later on as we use it to analyze an image.
Choosing a Vision Source
When working with the v4 Image API, you can connect to your image via one of the static methods on VisionSource.
First, if you have an image locally on disk, you can refer to it by passing an absolute or relative path as a string to the VisionSource.FromFile method:
string imagePath = "Snowscape.png";
VisionSource source = VisionSource.FromFile(imagePath);
Alternatively, if you want to reference a file that’s hosted online, you can do so with the FromUrl method:
Uri uri = new Uri("https://someimageurl.png");
VisionSource source = VisionSource.FromUrl(uri);
Note here that the URL referenced must be something that your Azure AI Services or Azure AI Vision resource can access. This can be a public URL, or you can refer to a private image in blob storage using a SAS URL, for example.
Both ways of getting an image result in a VisionSource instance. I like this approach as it separates the image source from the image analysis work.
Running Analysis
Now that we have our VisionSource and VisionServiceOptions, we can analyze the image.
We do this by first specifying the ImageAnalysisOptions we want to perform and then calling Analyze or AnalyzeAsync on an ImageAnalyzer object:
ImageAnalysisOptions analysisOptions = new()
{
Features = ImageAnalysisFeature.Caption |
ImageAnalysisFeature.Tags |
ImageAnalysisFeature.Objects |
ImageAnalysisFeature.People |
ImageAnalysisFeature.DenseCaptions |
ImageAnalysisFeature.Text |
ImageAnalysisFeature.CropSuggestions
};
using ImageAnalyzer client = new(serviceOptions, source, analysisOptions);
ImageAnalysisResult result = await client.AnalyzeAsync();
This will call out to Azure in a single call and analyze the image providing captions, tags, object detection, person detection, dense captioning, text-recognition, and crop suggestions.
The result of each of these operations is stored on properties in the ImageAnalysisResult object. If you do not request that Azure perform an operation, its corresponding property will be null on the result object.
Note that each operation you choose will incur a slight cost for the request and some operations may increase the duration of the call as well.
Interpreting Image Results
Let’s look at the results we get back from image analysis and discuss each of the features in turn as we go.
Captions
Captioning provides an overall caption for the entire image. The caption includes a Content string representing the caption and a Confidence value from 0 to 1 indicating how confident Azure is in the image.
The following line displays the caption and confidence as a percentage:
Console.WriteLine($"Caption: {result.Caption.Content} ({result.Caption.Confidence:P} Confidence)");
For example, my friend Shahed shared this still from a video he took from a plane during landing:

When Azure AI Vision sees this it captions it as:
a snow covered city with cars and buildings (62.30 % Confidence)
This is a fairly accurate result, particularly for an image without much detail or color. I’d have liked it to describe the image as aerial or elevated photography, but I’m happy with the result from a rather snowy picture.
Tagging
Tagging identifies common tags in the image. These tags indicate objects or themes believed to be present in part of the image or the entire image.
This can be helpful when you are looking at a large collection of photos (for example, family vacations over the years) and want to identify keywords for searching or indexing.
Tags works by providing a collection of ContentTag objects which each contain a string Name and a Confidence percentage from 0 - 1.
You can print all tags on an object in a single line using LINQ:
Console.WriteLine($"Tags: {string.Join(", ", result.Tags.Select(t => t.Name))}");
On Shahed’s image earlier, this produces the following result:
fog, winter, snow
When I use tagging on a different photo by Shahed of the Kobe Bell, I get many more tags:

This produces the following tags:
outdoor, winter, tree, plant, sky, japanese architecture, chinese architecture, snow, building, ground, shrine, place of worship
Note that tags may offer several different interpretations at different confidence levels. For example, the Kobe Bell represents a piece of Japanese architecture, but it is tagged as both Japanese and Chinese.
While tagging is less relevant for describing the image, I do sometimes see things in tags that are not represented by the caption. For example, the added context of fog from the aerial photograph.
Object Detection
Object detection is somewhat like tagging, but instead of just indicating the presence of something in an image, object detection gives you a bounding box for where in the image the object was detected.
You can loop over objects found with the following C# code:
foreach (DetectedObject obj in result.Objects)
{
Console.WriteLine($"Object: {obj.Name} ({obj.Confidence:P} Confidence) at {obj.BoundingBox}");
}
When I apply this code to a lovely image from my friend Pete, it detects a few objects:

Here it detects:
- Van (55.30% Confidence) at {X=267,Y=483,Width=244,Height=160}
- Land vehicle (52.20% Confidence) at {X=1761,Y=512,Width=110,Height=43}
Note how it tells me not just what it detects, but where in the image the object was detected.
Let’s clarify this by overlaying the bounding boxes for these two objects onto the image:

Note: if you’re curious how I generated this image, I used Azure Vision Studio which provides a graphical user interface for trying Azure AI Vision capabilities.
Now, there are a few issues with this results here:
- The vehicle in the driveway is a car, not a van. I think the snow on the windshield made it look like the back of a van to the image model
- The houses, stone wall, and telephone pole are not tagged
- The car at the extreme right edge of the image is not tagged
No image model is going to be perfect, and vision models may struggle with objects at the edges, at unusual angles, or in unusual lighting conditions. This has to do with the training images used to train the computer vision model not having sufficient examples of these types of scenarios. You can solve this problem yourself by training your own custom vision model on your own images if it presents a severe challenge.
People Detection
Person detection is like object detection, but oriented to only detect the location of people in images.
The code for this is very similar to object detection code:
foreach (DetectedPerson obj in result.People.Where(p => p.Confidence >= 0.7))
{
Console.WriteLine($"Person: ({obj.Confidence:P} Confidence) at {obj.BoundingBox}");
}
Note how we do not get a name property for the DetectedPerson class. All we know is that it was some person, not who or anything about the type of person.
Also note that I have a minimum confidence % I require of 70% in the results. Azure AI Vision has a tendency to provide multiple very small confidence % results for small pieces of images that it think might in some way resemble humans. Filtering things out below a given threshold helps remove these false positives.
Let’s apply this to a photo I took one snowy Christmas Eve:
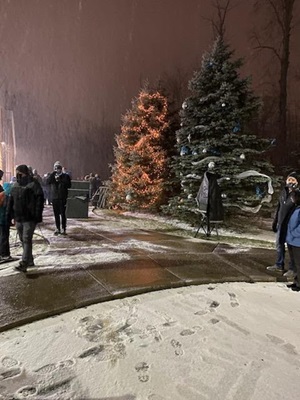
Here we see four people (with threshold filtering in place):
- Person (89.84% Confidence) at {X=11,Y=262,Width=62,Height=174}
- Person (86.75% Confidence) at {X=73,Y=256,Width=42,Height=121}
- Person (84.74% Confidence) at {X=425,Y=273,Width=54,Height=163}
- Person (75.00% Confidence) at {X=0,Y=270,Width=22,Height=150}
You can visualize these people by overlaying the bounding boxes onto the source image as before:
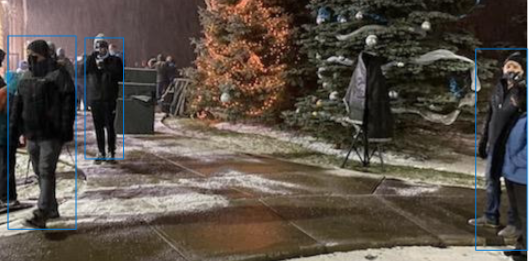
This deliberately doesn’t provide any facial recognition capabilities to prevent misuse of the computer vision algorithm.
Dense Captions
Dense captioning is what happens when you combine object detection and captioning.
Dense captions are captions localized to specific interesting parts of an image.
For example, Pete took a lovely image of snow on a fence and treeline as shown here:

When put this image through dense captioning, you get multiple captions applied to different rectangles in the image as shown in Azure Vision Studio:
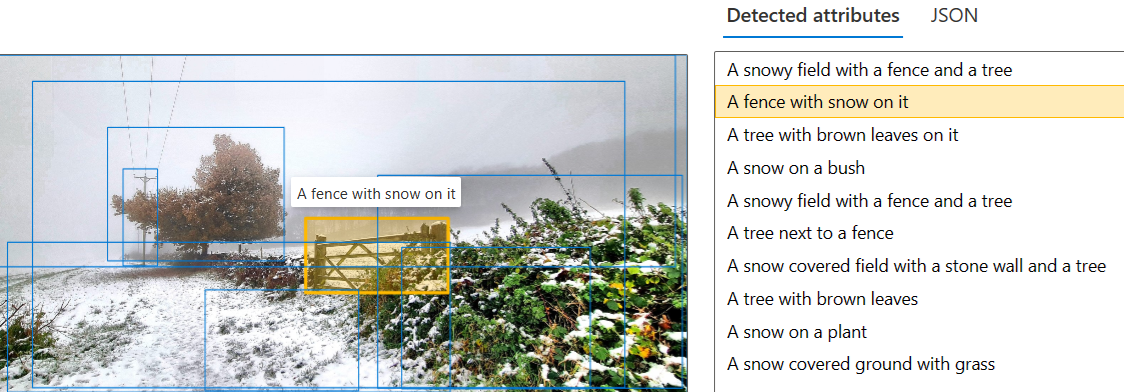
The code for enumerating these results should be somewhat familiar by now:
foreach (ContentCaption caption in result.DenseCaptions)
{
Console.WriteLine($"Dense Caption: {caption.Content} ({caption.Confidence:P} Confidence) at {caption.BoundingBox}");
}
While the dense captions can be somewhat repetitive, I find that they tend to tell a very good overall story of the picture when put together.
One final note: dense captioning seems to always include a caption for the entire image, so you shouldn’t need to do both dense captioning and standard captioning on the same image.
Text / Optical Character Recognition
Azure AI Vision offers optical character recognition (OCR) capabilities for reading incidental text in images.
This capability is good at rotating, skewing, and reading text at odd angles and with distortions and I’ve found it remarkably effective at reading printed, handwritten, and even cursive text.
To stretch OCR to its limits, let’s try it out in the most unfair way I can think of: showing it a picture Sergio took in Finland of a ski lift and asking it to identify text in the image:

“But Matt”, I hear you say, “There’s no text in that image!”
This is what I thought when I first saw the image, but Azure actually found some text to analyze on the front-most chair:

It turns out that the chairlift does have some text in Finnish.
We can enumerate through the lines of text in the image in the following way:
foreach (DetectedTextLine line in result.Text.Lines)
{
Console.WriteLine(line.Content);
}
Doing so recognizes the Finnish string:
Alle 3 huntla Outun sis
That’s nearly correct for a random distant chairlift in Finnish.
The correct text would be:
Alle 3 tuntla Ouluun
Followed by:
Oulun Yliopisto
When I put this through Bing translator moving from Finnish to English I get:
Less than 3 hours to Oulu University of Oulu
While the OCR wasn’t 100% accurate in this case, I legitimately didn’t even recognize that there was text in the image to begin with, so this was a case where Azure was able to spot text I missed and come close to generating an accurate transcription of it.
Azure offers a bounding polygon around the text as well as the ability to enumerate over the words in an individual line of text to get the string for the word, the confidence score, and a bounding polygon around that individual word.
Crop Suggestions
If you have an image that you need to crop down to a specific aspect ratio, Azure can help with that. Azure AI Vision uses smart cropping to maximize the focus on objects of interest in your image while still making a crop.
This means that if you have interesting objects at the edges of your image, a default crop might crop out interesting parts of the image while Azure AI Vision will focus on making the interesting parts of the image still visible.
As an example, lets' look at this image of a snowy neighborhood Kit Eason took from an upper floor:

When you ask Azure to generate crop suggestions for an image, you can either let Azure recommend an aspect ratio or provide aspect ratios of your own you are interested in.
Let’s say that we wanted a 1.5 aspect ratio where the width is 150% the size of the height of an image.
We can specify this by altering our ImageAnalysisOptions declaration:
ImageAnalysisOptions analysisOptions = new()
{
CroppingAspectRatios = [1.5],
Features = ImageAnalysisFeature.Caption |
ImageAnalysisFeature.Tags |
ImageAnalysisFeature.Objects |
ImageAnalysisFeature.People |
ImageAnalysisFeature.DenseCaptions |
ImageAnalysisFeature.Text |
ImageAnalysisFeature.CropSuggestions
};
Following that, Azure AI Vision will provide cropping suggestions:
foreach (CropSuggestion suggestion in result.CropSuggestions)
{
Console.WriteLine($"Crop Suggestion: Aspect Ratio: {suggestion.AspectRatio}, Bounds: {suggestion.BoundingBox}");
}
In our case, that winds up being this portion of the image:

Notice how Azure respected our aspect ratio while also keeping the most interesting part of the image centered in the crop?
One final note: while the v3.2 Image APIs provided new images through cropping, the v4 API only gives you the bounding box you’d use to crop the image. You’ll need to crop the image yourself using an image library of your choice.
Background Removal
Now that we’ve seen all the image analysis options, let’s take a look at background removal, one of the newest parts of Azure AI Vision.
With background removal you can identify foreground and background layers of images and automatically delete the background layer resulting in a transparent image.
Let’s show this with a lovely close-up photo Peter O’Hanlon took of a branch:

We can run this image through an image segmentation filter to remove its background with the following code:
ImageAnalysisOptions analysisOptions = new()
{
SegmentationMode = ImageSegmentationMode.BackgroundRemoval,
Features = ImageAnalysisFeature.None
};
using ImageAnalyzer client = new(serviceOptions, source, analysisOptions);
ImageAnalysisResult result = await client.AnalyzeAsync();
File.WriteAllBytes("BackgroundRemoved.png", result.SegmentationResult.ImageBuffer.ToArray());
Once this completes, the BackgroundRemoved.png will be created with the raw bytes of the final image. This results in this image:

Pretty nifty!
Note that you cannot combine SegmentationMode and Features in the same request. Attempting to analyze image features and perform image segmentation will result in an error.
Also note that the current options for ImageSegmentationMode include background removal (which we just did) as well as foreground matting.
Foreground Matting produces an alpha mask of your image that shows how Azure distinguishes between the foreground and background layers.
An example foreground matte is shown here:

I expect Microsoft to add more capabilities to the SegmentationMode and am excited to see how the Azure AI Vision API grows over the coming years.
Closing Thoughts
Hopefully you’ve now seen how Azure AI Vision can provide insight into digital images. While many real-world scenarios for computer vision exist from powering robots and vehicles cars to detecting manufacturing defects, I think there’s also a lot of personal uses of computer vision.
For example, you could take your photo album and run it through Computer Vision to produce a set of searchable tags or to help crop images down to a specific aspect ratio. You could also generate textual descriptions of your images for family members or friends who have vision impairments.
I personally love the computer vision capabilities of Azure and I hope you get a lot of enjoyment out of them this winter and beyond.

