The 3 Core Machine Learning Tasks
Understanding Classification, Regression, and Clustering in Machine Learning
The Three Core Tasks
Let’s talk about the 3 core machine learning tasks: Classification, Regression, and Clustering.
These are the three tasks you’ll want to focus on when learning data science.
This content is also available in video form on YouTube
Not only are these 3 tasks very common things you’ll want to do for your data science projects, but these projects will help you build the skills and knowledge you need to perform the more specialized aspects of machine learning.
Let’s get started.
Classification
Imagine you were a bank and had historical information about people who have taken out loans and whether or not those loans had been repaid. Using this data set, you could train a machine learning model to predict whether a person is likely to pay back a loan they’re requesting.
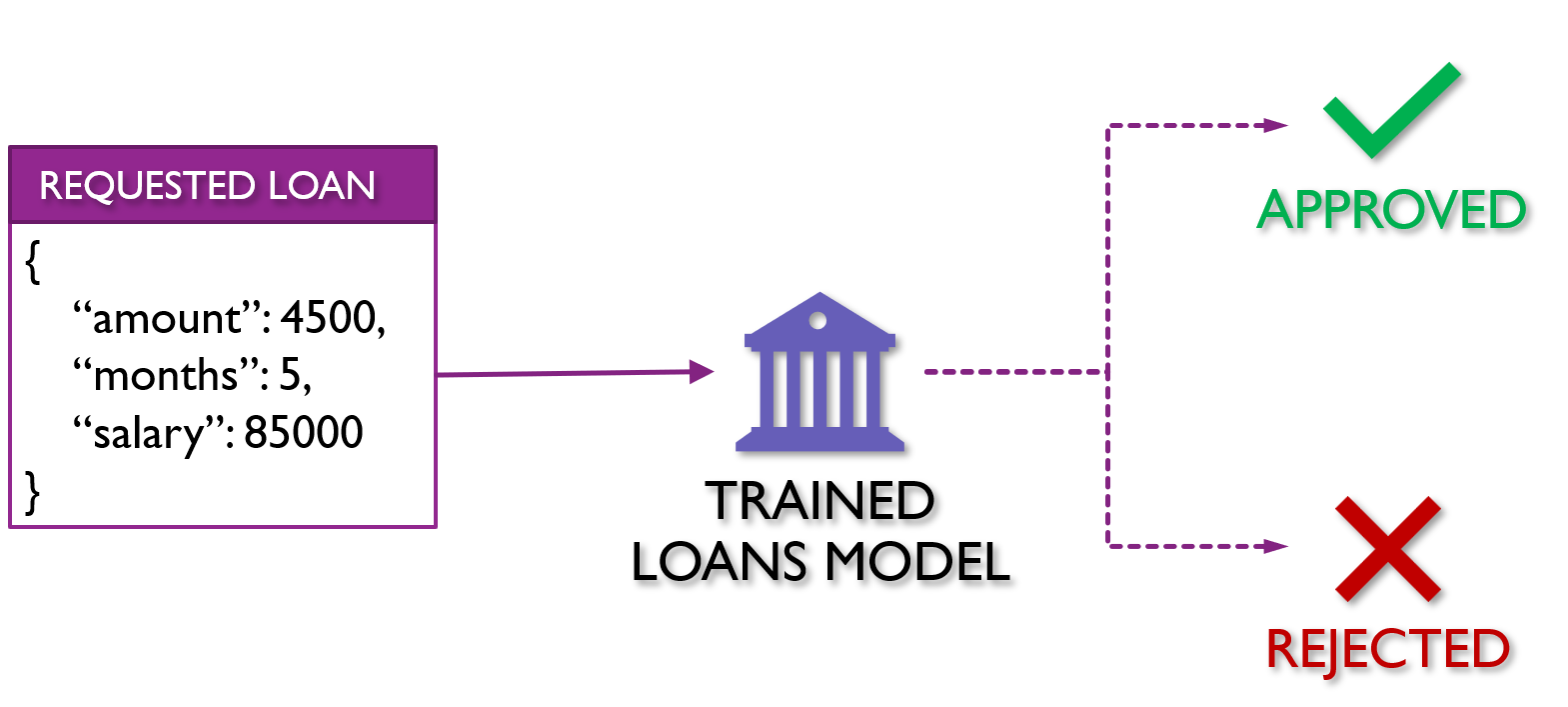
This is an example of classification: predicting what categorical label something might belong to given historic data.
In this case the label I’m predicting would be whether the loan would be repaid and the features relevant for that might be things related to a person’s annual income, the value of the home, the term of the loan, and the amount being requested, which might look like the following data:
| Borrowed | Months | Salary | Repaid? |
|---|---|---|---|
| $4,200.00 | 24 | $75,000.00 | Yes |
| $50,000.00 | 60 | $35,000.00 | No |
| $100,000.00 | 3 | $100,000.00 | No |
| $25,000.00 | 2 | $65,000.00 | Yes |
| $1,500.00 | 1 | $70,000.00 | No |
Example Project: Classifying Die Hard
Another example of classification is a machine learning experiment I did last year around the movie Die Hard.
My wife and I were debating if Die Hard should be considered a Christmas movie. To solve this problem, I built a machine learning model around historical movie information that included both Christmas movies and non-Christmas movies.
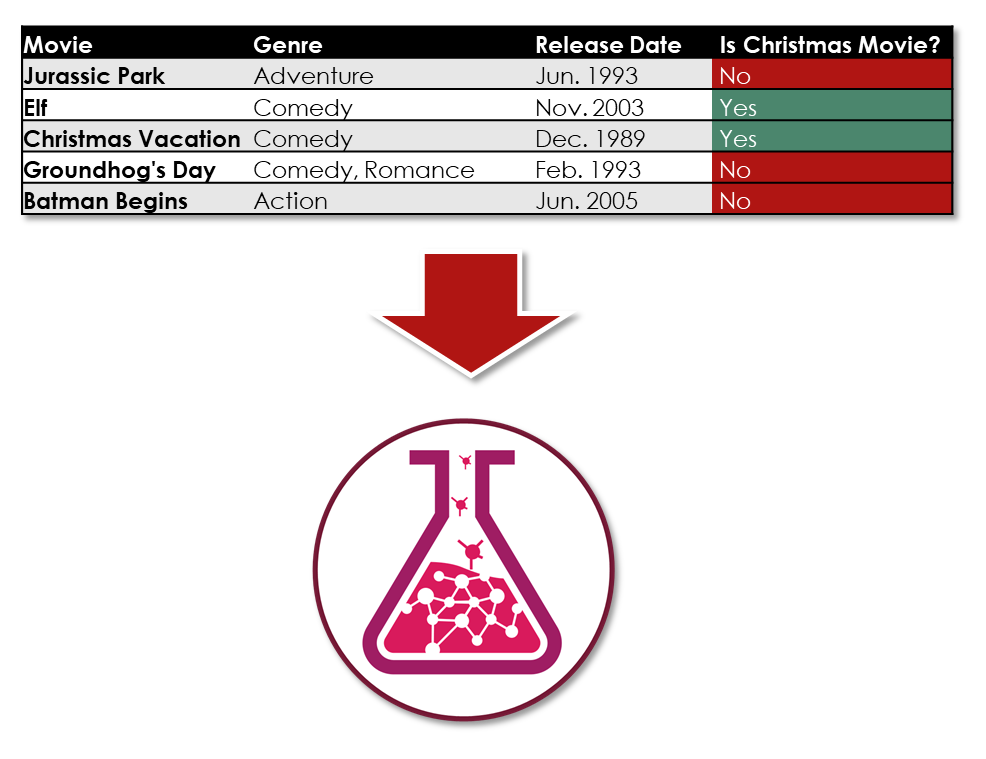
Once this model was trained, I asked the model if Die Hard should be considered a Christmas movie and it was able to predict the expected value of the Is Christmas Movie label for that movie.
Both Die Hard and the loan approval models are examples of binary classification where something is going to be one of two possibilities.
Other examples might be predicting if a customer or employee will leave your organization or if a mole is cancerous.
Multi-Class Classification

Sometimes you want to predict if something is one of several different possibilities. When there are 3 or more possibilities, we call this multi-class classification.
Example Project: ESRB Game Rating Prediction
For example, if you have an unreleased video game and wanted to predict the Entertainment Software Rating Board (or ESRB) rating for the game’s content, you could build a classification model and train it on historical games, their content, and the rating they were given.
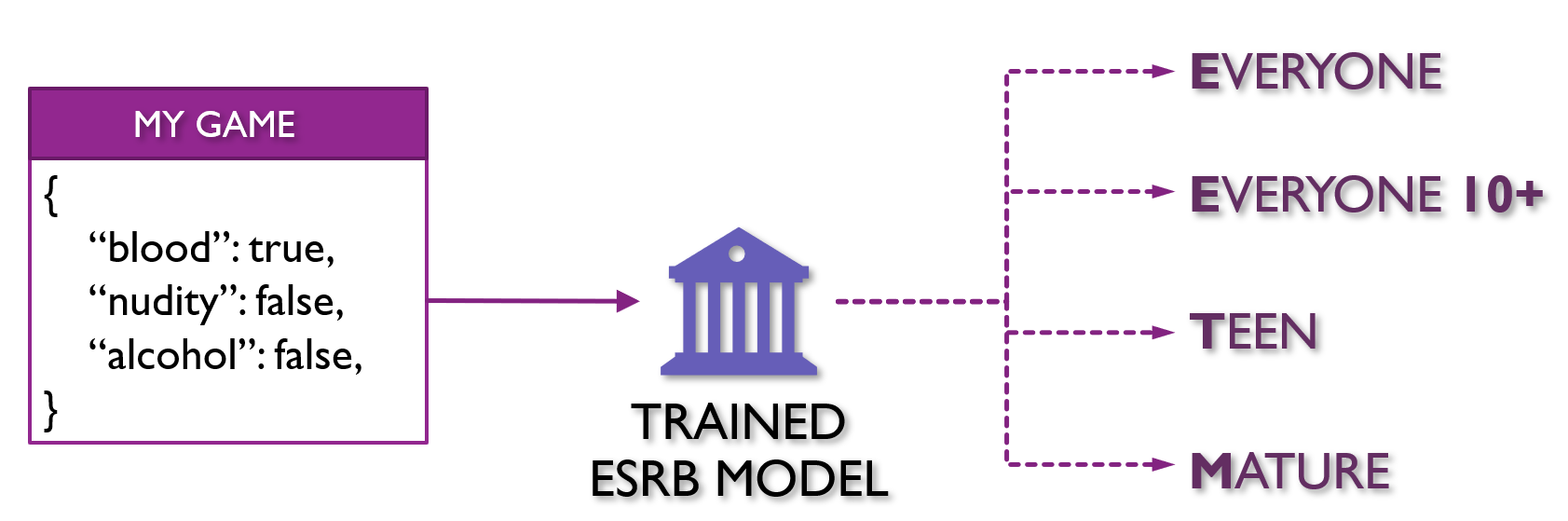
This trained model would then be able to predict ESRB ratings for video games that had yet to be released and generate some degree of probability that a game might be in any given rating.
Using this, I could determine how likely a new video game was to be given a specific rating given historical video game releases.
Regression
Next we have regression models. If classification is all about predicting a single categorical label, then regression is about predicting a single numerical label instead. In other words, we’re no longer predicting what something is, but instead we’re predicting how much of something.
For example, you could train a regression model to predict the how much a used car would sell for given historical data on recent used car sales in the area.
| Model | Year | Mileage | Original MSRP | Resell Price |
|---|---|---|---|---|
| Road Hog | 2010 | 14,065 | $22,500 | $15,000 |
| Raging Puma | 2007 | 78,113 | $28,000 | $19,750 |
| Road Hog | 2010 | 7,500 | $22,500 | $18,500 |
| Teen Trainer | 2001 | 230,574 | $16,500 | $900 |
| Raging Puma | 2008 | 95,782 | $29,500 | $20,550 |
Example Project: Car Defrosting Prediction
A regression experiment I did in the past involved predicting the number of minutes I’d need to spend in the morning scraping off my car’s windshield.
I built a data set over some time by automatically tracking overnight weather predictions and then manually recording the number of minutes I spent defrosting my car.
By the end of the winter I had a model that was trained sufficiently to be able to predict how much time I’d need to scrape off my car’s windshield.
Of course, by the next winter we had a garage and my model was worthless, but this was a good example of a regression model in action.
Clustering
Finally, we reach clustering. Clustering is the process of determining groups of data points based on their similarities.
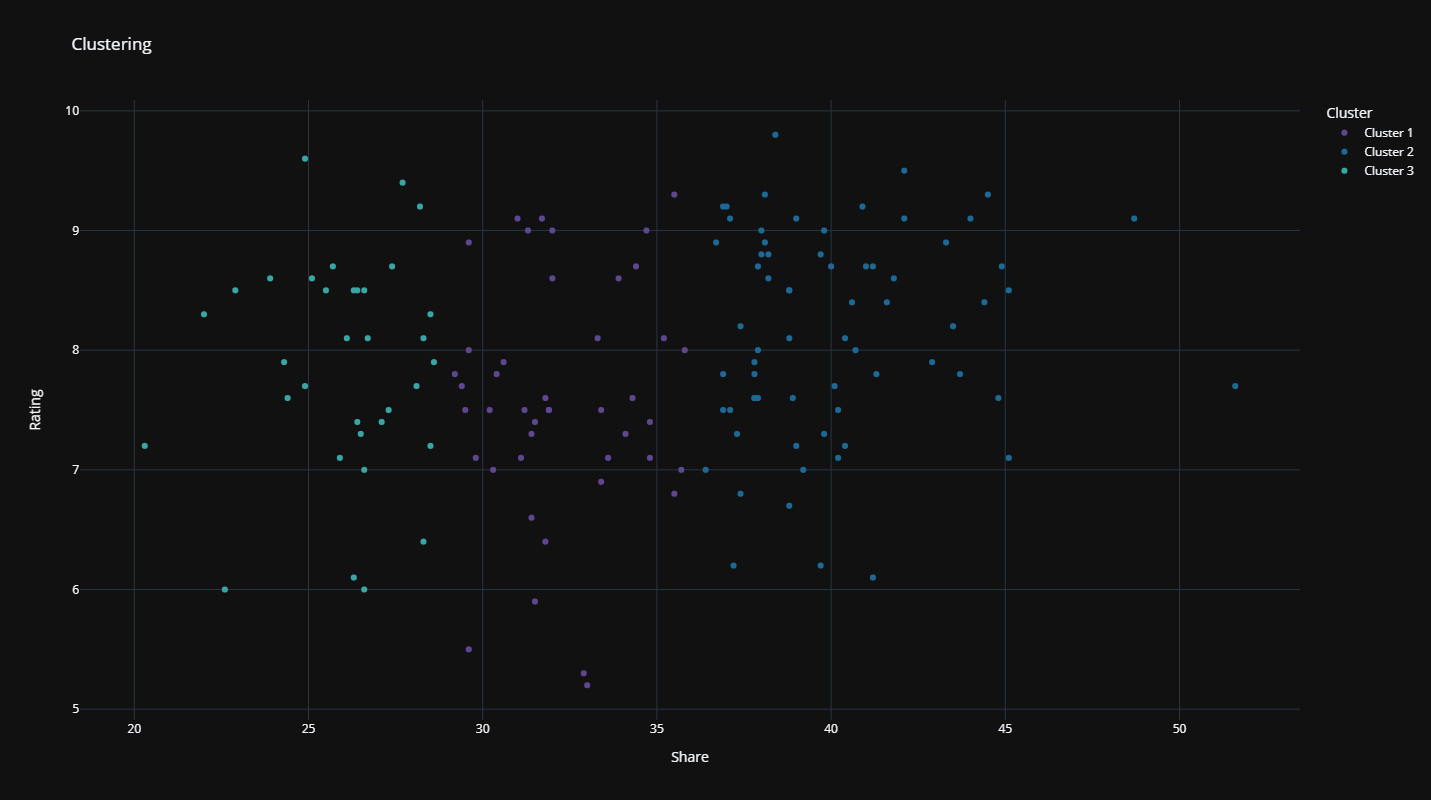
Clustering is sometimes used for things like segmenting different types of users for marketing strategies based on their usage habits.
Clustering is also used for geographical data. If I wanted to host 5 events across the world to meet every person who watched this video in a given year, a clustering algorithm could determine the optimal places to hold each one of those events.
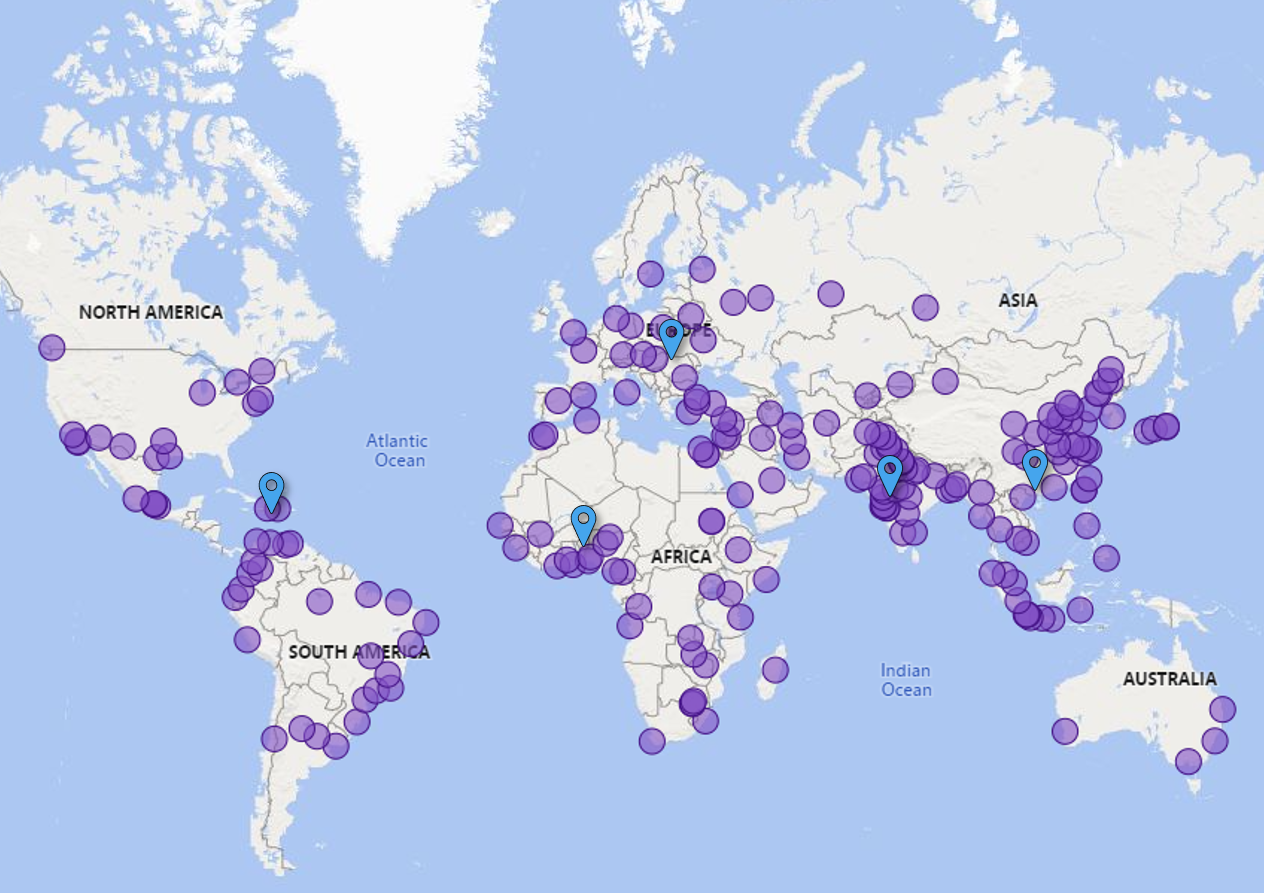
Some of you would still need to travel farther than others, but the average person’s travel distance would be as good as we could make it.
Conclusion
That covers the basics of the three core types of machine learning: classification, regression, and clustering.
As you get started with machine learning, I strongly encourage you to start with classification or regression.
In fact, a standard experiment for new data scientists is to start out with a binary classification experiment that predicts if a passenger on the Titanic would have lived or died based on their ticket information. And no, this is not a joke. Check it out and see!
Until next time, happy coding and keep learning!

