What is Azure Synapse Analytics?
A high-level overview of Azure's enterprise-level data engineering solution
Recently I had the opportunity to spend some time studying Azure Synapse Analytics and I wanted to share a high-level summary of what I learned so you can determine if it is a good match for your data processing needs.
This content is also available in video form on YouTube
Introducing Synapse Analytics
In 2019, Microsoft rebranded their existing Azure SQL Data Warehouses product to Azure Synapse Analytics and began overhauling its features. The following year Microsoft unveiled their “workspaces” feature set featuring dedicated SQL pools and many more of the features that I’ll cover in this article.
At its core, Synapse Analytics takes a number of existing parts of Azure and wraps them together under a single unified banner and backs it with a powerful and scalable data processing engine. Azure Synapse Analytics gives us a single unified product that can repeatably ingest data from data lakes, data warehouses, relational databases, and non-relational databases.
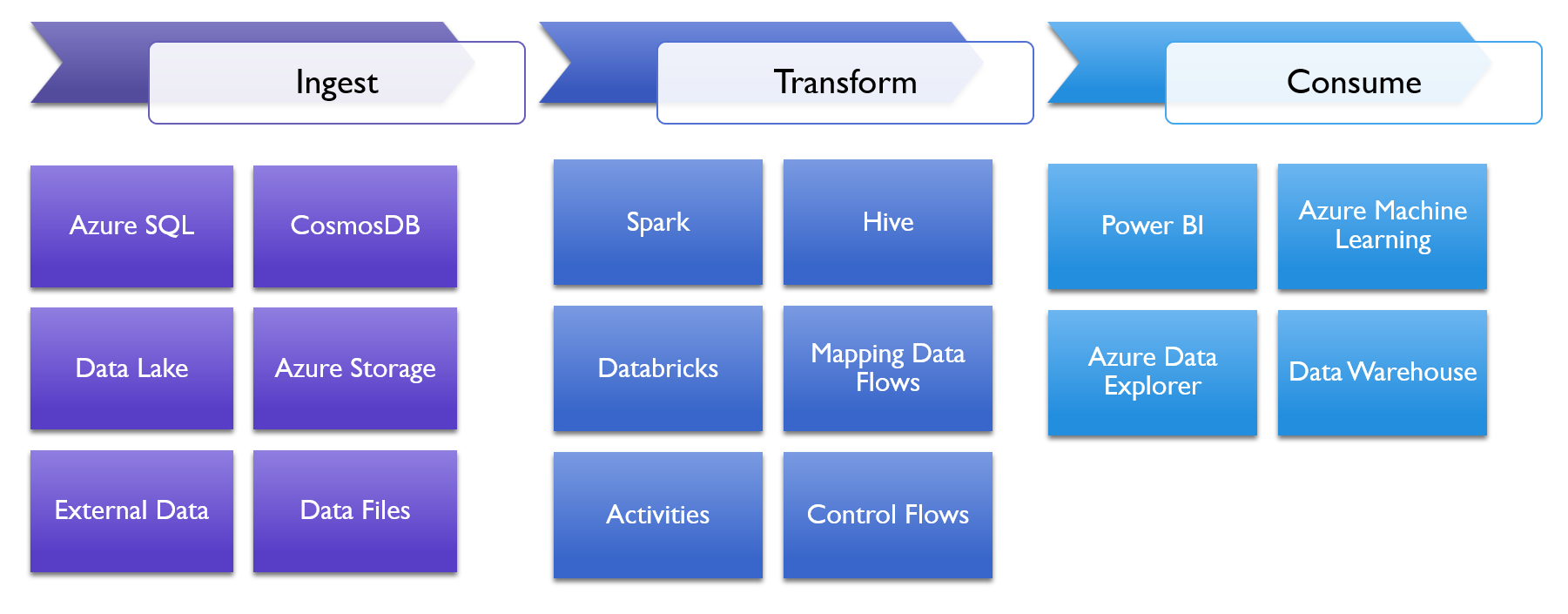
Synapse Analytics can then transform and store this data using the same core pipeline features and code from Azure Data Factory, but it does it using distributed processing technologies with Spark pools and SQL pools.
Synapse Analytics lets us consume this data either by storing in a data warehouse or by providing easy ways of integrating with Power BI for analysis and Azure Machine Learning for machine learning model generation.
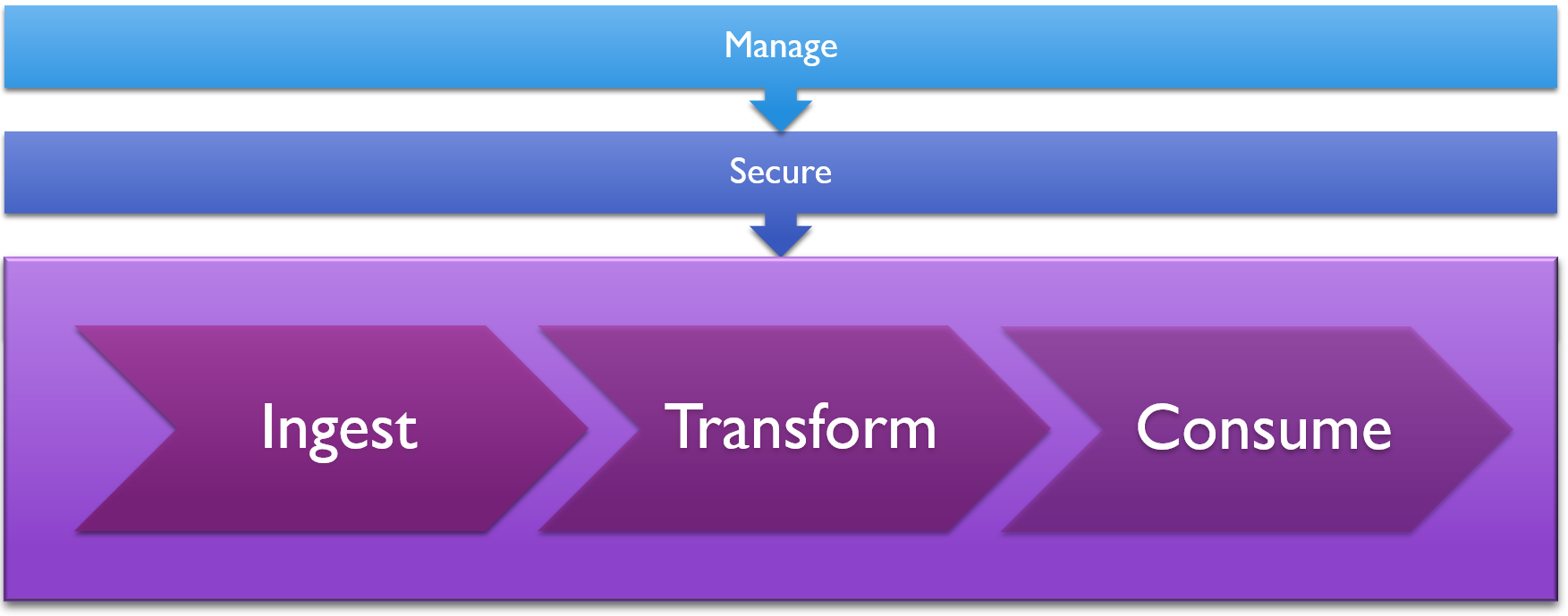
This lets Azure Synapse Analytics serve as an ETL, ELT, and batch processing pipeline for large-scale data sources and support real-time analytics needs. And Synapse Analytics does all of this in a way that is easy for enterprises to secure and monitor.
What about Azure Data Factory?
To some of you, this may sound a little familiar to Azure Data Factory, so let’s talk briefly about the difference between the two.
Azure Data Factory lets users define their own extract / transform / load and extract / load / transform pipelines that consist of a wide variety of activities. This effectively lets teams build custom solutions for data engineering in the cloud.
Now Azure Data Factory does have some limitations, however. First of all, while you can integrate a lot of things into it, the process for doing so is not very centralized. Additionally, it’s hard for an organization to get an accurate glimpse into all aspects of their service offering or secure things in a unified way.
This effectively makes Azure Data Factory powerful, but limited in its applications for the enterprise.
Azure Synapse Analytics is designed to address this gap while providing additional features and capabilities.
Ingesting Data
In Synapse Analytics you can define any number of data sources to feed into your Synapse workspace.
These sources could be SQL databases like Azure SQL or Postgres, or they could be NoSQL databases such as CosmosDB. Synapse Analytics also supports blob, file, and table storage as well as data lakes and Spark-based data systems.
One thing to highlight here is that data can also be ingested from outside of Azure via connectors to other cloud providers or even by installing an Integration Runtime on-premises to provide self-hosted data to Synapse Analytics in a hybrid cloud environment.
Once you’ve configured data sources, they’re now available to be copied into your Azure Synapse Analytics data lake.
Copy Data Tool
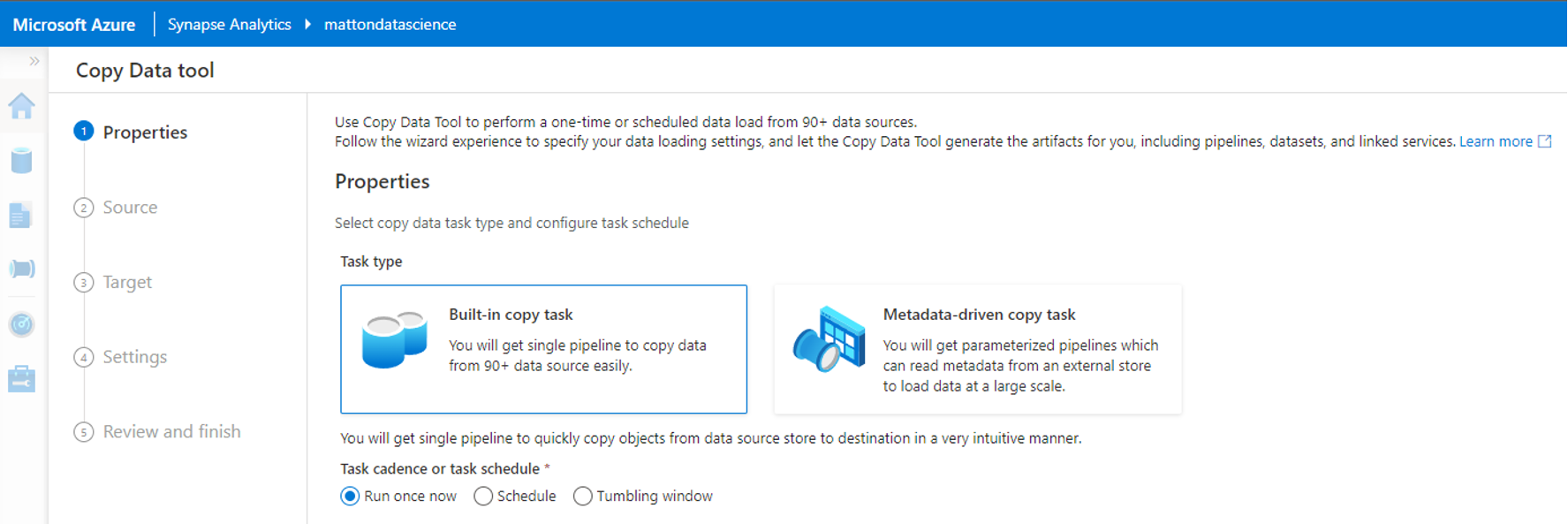
Microsoft gives us a very robust Copy Data Tool that allows you to copy data from your data sources into your data lake. This copy operation can be run manually, can be given a loose schedule, or be run on a tumbling window for recurring intervals like weekly tasks.
Mapping Data Flows
Synapse also lets you define something called a Mapping Data Flow that allows you to aggregate, filter, sort, and otherwise transform the data you’re loading. You can even merge together multiple data sources via join operations!
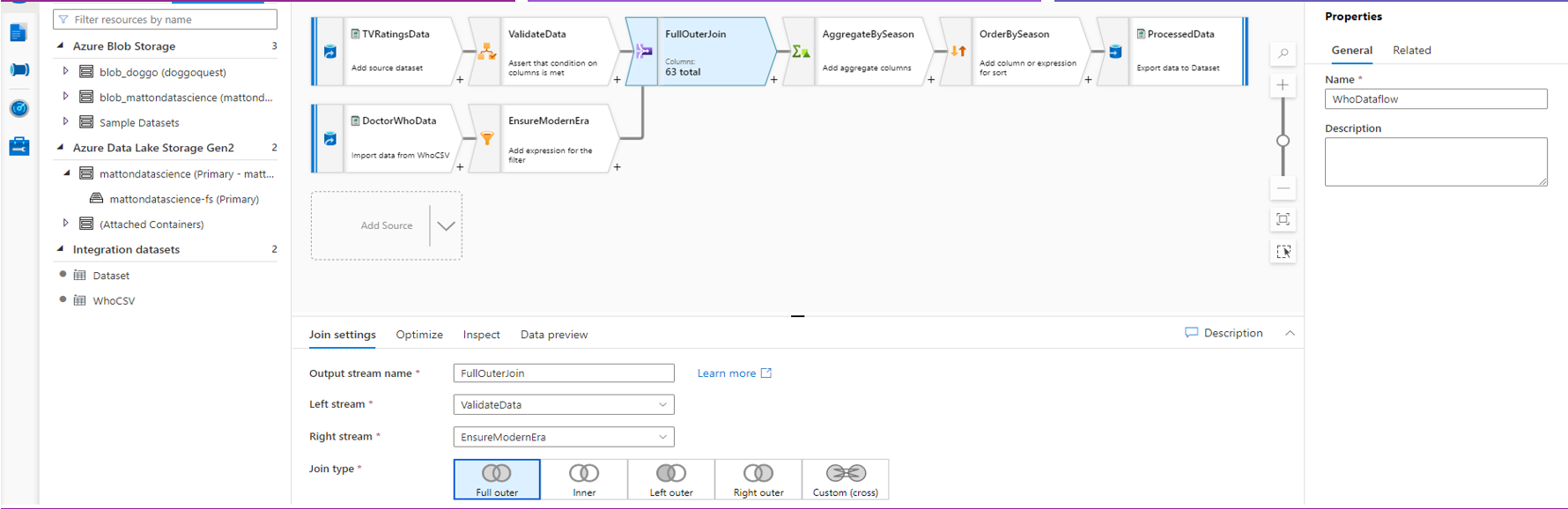
If you’ve encountered Mapping Data Flows before in Azure Data Factory, Azure Synapse Analytics actually shares a lot of the same underlying code so you should be familiar with many of the features.
Pipelines
Let’s talk about transforming data.
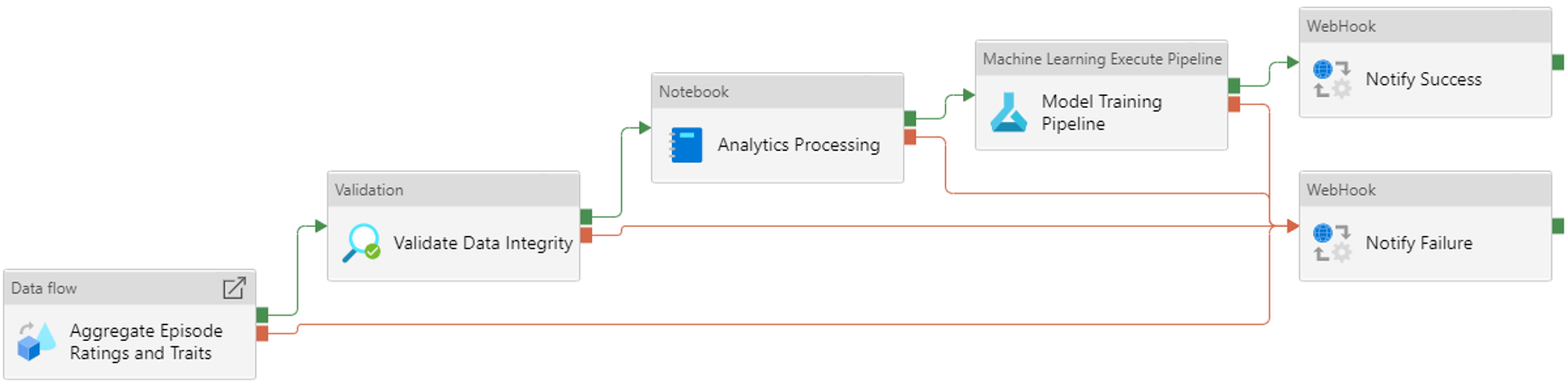
Synapse allows you to define pipelines that can trigger mapping data flow and data copy tasks.
Pipelines has over 90 different activities for data processing and transformation, including the ability to run custom code in Spark or Databricks notebooks.
Scalability
Let’s talk about the scalability factors of Synapse because this is where Synapse Analytics really shines.
One of the reasons that Synapse is so scalable is because it relies on two separate but related pools: a SQL pool for querying and a Spark pool for data processing.
Synapse uses SQL pools to query its data in a very scalable manner.
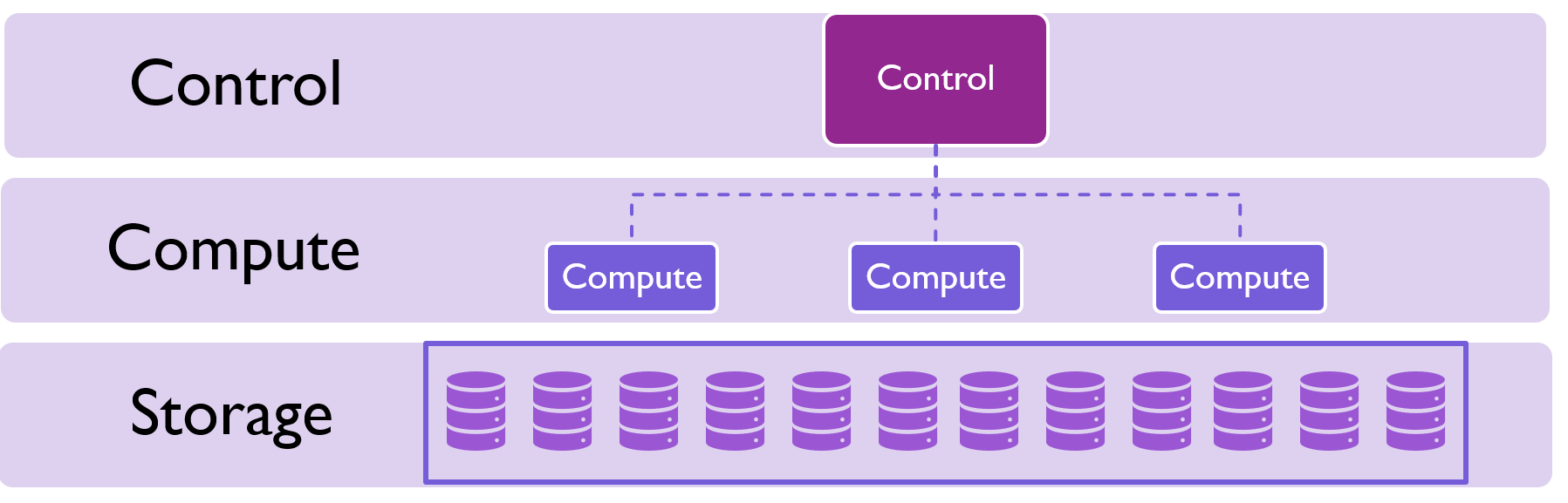
In a SQL pool there is a single control node which receives and distributes queries to individual compute nodes. Compute nodes are responsible for executing queries against data storage and returning results to the control node.
There are two different SQL pool models available: Dedicated SQL pools and Serverless SQL pools.
Dedicated SQL Pools
Dedicated SQL pools are closer to a traditional database model where you are paying for dedicated resources based on how many compute nodes you need.
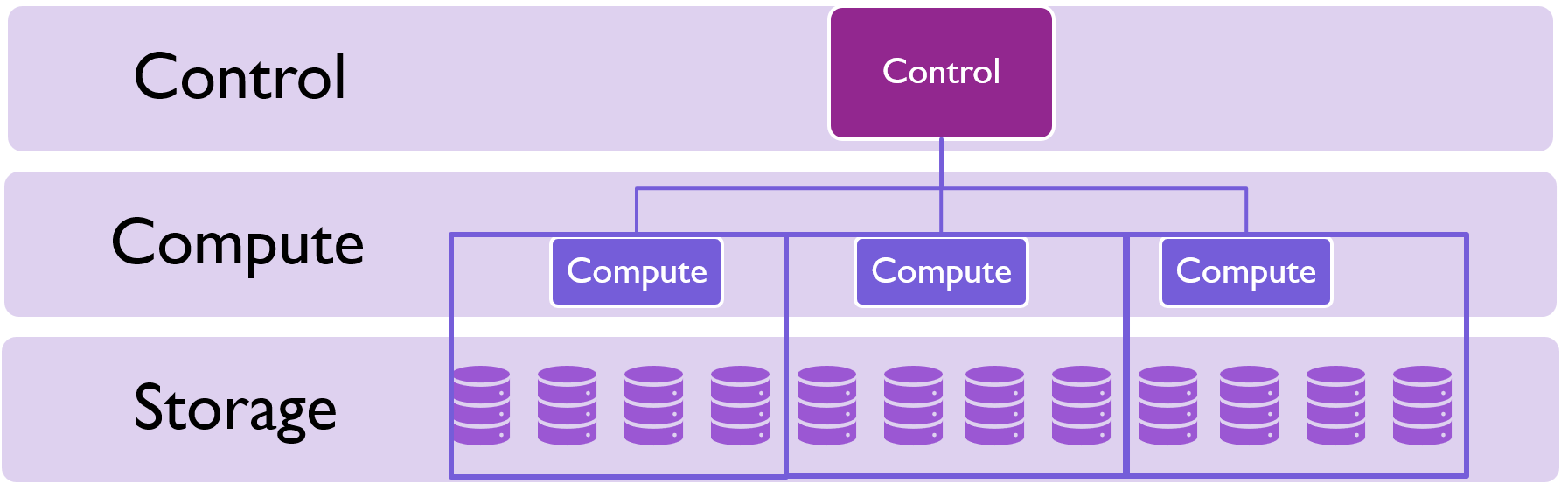
When a query comes in, the control node figures out which compute nodes have relevant data and asks them to run specific queries against their data. This data is then returned to the control node.
Compute nodes can be run in round robin mode where data is distributed evenly, in hashed mode where different data values go to different compute nodes, or in replicated mode where the same data is stored on every compute node.
Each of these modes have different scalability and performance characteristics:
- Round robin is the default and has average overall performance characteristics.
- Hashed mode performs well for larger data stores but does lead to imbalanced loads across compute nodes.
- Replicated mode is best for small data stores that need very high performance at the expense of duplicating data across all nodes.
Serverless SQL Pools
Dedicated SQL pools are great for high performance and high volume data processing, but they can be a bit too expensive for many smaller workflows.
Serverless SQL pools address this by operating in a different model. Instead of declaring the number of compute nodes you want up front, Azure stores your data outside of its compute nodes. When you need to run a query, the control node analyzes the complexity of the query and sends it to an appropriate number of compute nodes from Azure’s available compute nodes for the entire region. These compute nodes then access your stored data.
Serverless SQL Pools aren’t as fast as a dedicated pool, but they are usually cheaper for scenarios where you are infrequently querying your data store.
Spark Pools
If SQL Pools are what we use to query our data, Spark Pools are what we use to work with the results.
Synapse Spark is Microsoft’s variant on Apache Spark that is purpose-built for Synapse Analytics and can run dedicated notebooks to run custom code against data in your data lake.
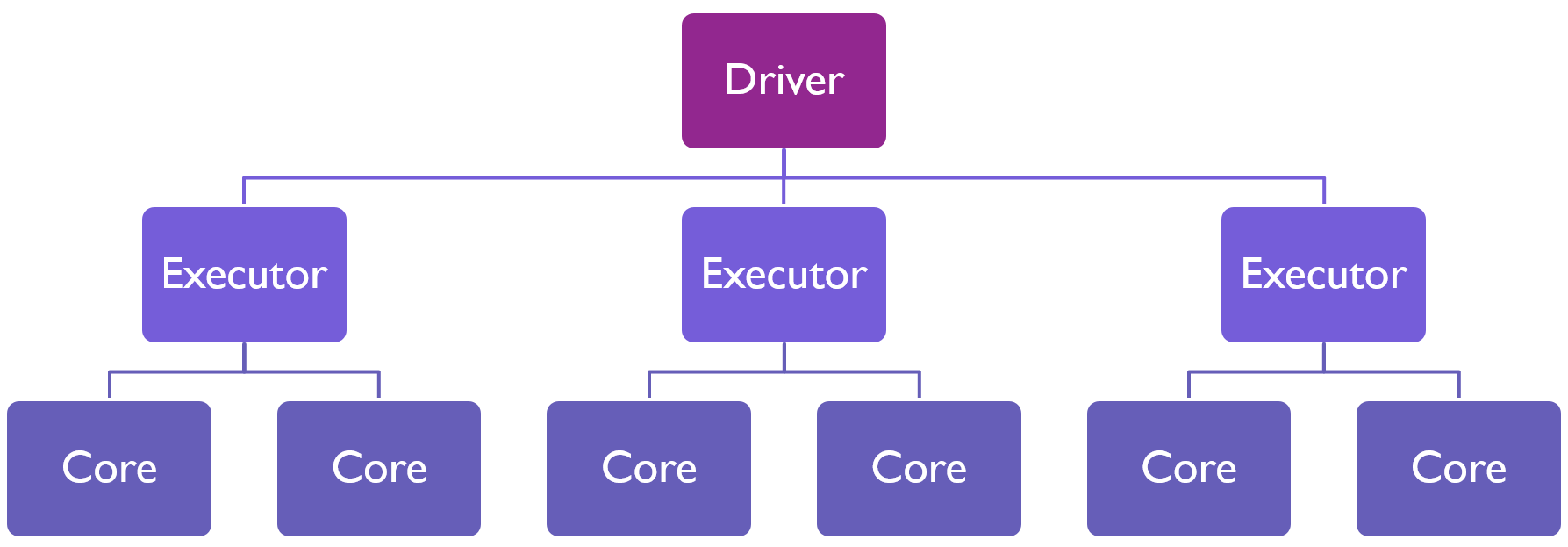
Like SQL Pools, Spark Pools follow a distributed model where a single Driver node hands off tasks to executors who then run those tasks in slots in the various cores they have available. This allows Spark Pools to dynamically scale up and down to meet your analytical needs - or even shut down entirely when not used.
Spark notebooks can run code in a number of languages:
- Spark SQL
- Python
- C#
- Scala
Notably, Spark notebooks cannot run any R code as of this moment.
Consuming Data via Integrations
Once data is loaded, it can be sent to a number of services outside of Synapse Analytics.
Most interestingly to me, you can use Synapse to trigger Azure Machine Learning pipelines and even generate Azure Automated ML code in notebooks from existing datasets.
On the data analysis side of things, Power BI can be linked to Synapse Analytics to provide a dedicated visualization tool allowing users to report on data in the data lake or create dashboards for key stakeholders.
Azure Data Explorer is an interesting data exploration and visualization service that seems to be rapidly growing at the moment and there are early signs of promising integrations between the two services as well.
Synapse Analytics as your Enterprise Data Pipeline
Clearly we can do a lot with Synapse Analytics, but it has some solid enterprise capabilities to mention as well.
Synapse Analytics gives us a dedicated central pane to monitor and manage all aspects of the data warehouse and processing pipeline, including both our SQL pools and our spark pools.
Additionally, Azure’s standard identity management capabilities can be fully applied here including managed identities, service principles, private endpoints, and firewall rules.
Finally, data security is alive and well with Azure giving us encryption at rest via transparent data encryption, column and row security to restrict who can see what data, and data masking for sensitive data.
Summary
Azure Synapse Analytics wants to be the cloud-based backbone of your entire data infrastructure. It offers the scalability and management features needed to meet the needs of the enterprise and has a usage-based pricing model and serverless options to make Synapse Analytics viable for individuals and small businesses as well.
Overall, Synapse Analytics is a very powerful and capable service for your data processing needs and integrates well into other offerings - including Azure Machine Learning.

