
Converting Pandas DataFrames to Azure Datasets
Migrate your Pandas DataFrames to Azure Machine Learning and back again
Before machine learning can be accomplished, data is frequently cleaned in Python using Pandas DataFrames to filter, clean, sort, and aggregate data into a more usable format.
But if you, like me, prefer to use the Azure ML Python SDK to help augment your data science tasks, you’ll need to convert your Pandas DataFrame to an Azure Machine Learning Studio Dataset.
Thankfully this process is easy (and reversible) using the Azure ML Python SDK.
What is a Dataset?
Azure Machine Learning relies on registered Datasets in order to run cloud-based machine learning. These custom Datasets are really just a pointer to file-based or tabular data in a blob storage or another compatible data store and are used for Automated ML, the Designer, or as a resource in custom Python scripts using the Azure ML Python SDK.
You don’t have to use Datasets for all machine learning, however. It’s entirely possible to use the Azure ML Python SDK and local compute resources to train machine learning models outside of Azure, then register or deploy those models into Azure Machine Learning. However, to experience the full breadth of features on Azure, you should register your data sources as Azure Datasets.
Converting from a DataFrame to an Azure DataSet
Let’s say you have an existing Pandas DataFrame with some simple data like this:
import pandas as pd
product_price_data = [['Transparent Aluminum', 5.99], ['Unobtanium', 9.88], ['Azurite', 12.35]]
df = pd.DataFrame(product_price_data, columns=['Name', 'Price'])
The resulting DataFrame would look something like this:

This is great! Using Pandas we can add and remove columns, filter and sort data, and generally do all the powerful tasks we’d need to for cleaning purposes.
However, we could not submit this Pandas DataFrame to Azure to start a machine learning experiment before converting it to a DataSet.
The process for this is fairly straightforward:
- Connect to an Azure Machine Learning Workspace
- Get the datastore to upload the data to
- Register the DataFrame as a tabular dataset
I have a small article detailing the process of connecting to an Azure Machine Learning Workspace, but typically this process is accomplished via the Workspace.from_config() method paired with a config.json from your workspace.
Once you have a workspace, the process for getting its associated blob storage is simple: datastore = ws.get_default_datastore()
Finally, we call Dataset.Tabular.register_pandas_dataframe with the dataframe, the target datastore, and the name for the new datastore.
Overall, the code for this process is going to be something like the following:
from azureml.core import Workspace, Dataset
import pandas as pd
# Connect to the Workspace
ws = Workspace.from_config()
# The default datastore is a blob storage container where datasets are stored
datastore = ws.get_default_datastore()
# Register the dataset
ds = Dataset.Tabular.register_pandas_dataframe(
dataframe=df,
name='NHL-Penalties-2020',
description='A breakdown of penalty minutes per game matchup',
target=datastore
)
# Display information about the dataset
print(ds.name + " v" + str(ds.version) + ' (ID: ' + ds.id + ")")
One interesting note here is that if your workspace already has a dataset with the same name your dataset will be uploaded as a new version of that dataset. This is handy if you make tweaks to your dataset over time because you can now get access to old versions of your data for comparison purposes.
After the register_pandas_dataframe call is complete, your dataset should now show up in Azure Machine Learning Studio and will be retrievable via the SDK as well:
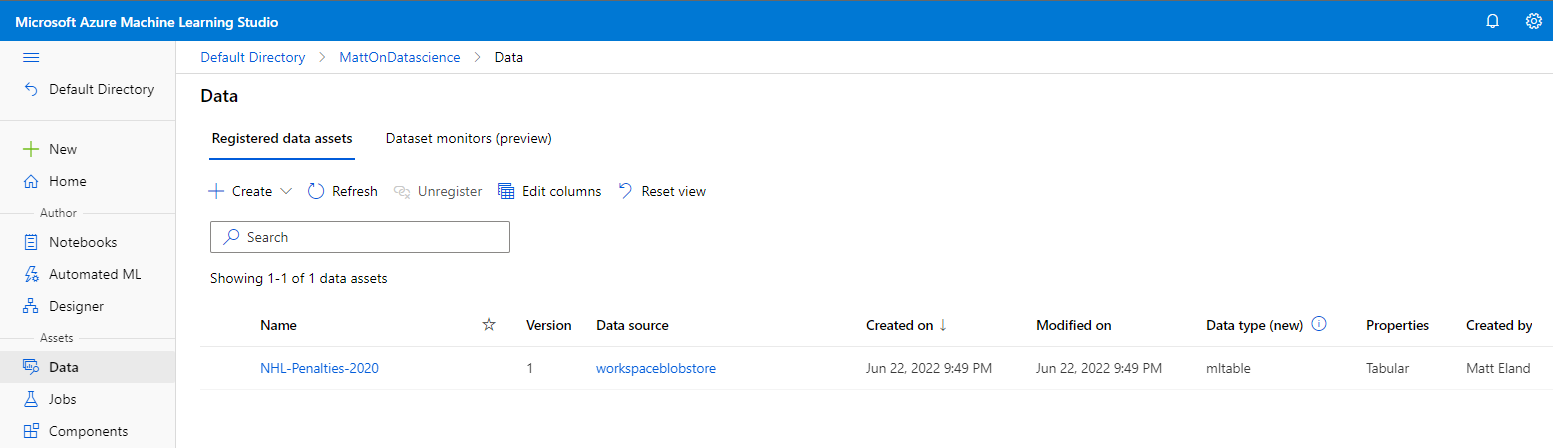
Converting from a DataSet to a DataFrame
In the rare occurrence where you might want to convert from a dataset back to a Pandas DataFrame, this can be done via the following code:
from azureml.core import Workspace, Dataset
import pandas as pd
# Connect to the Workspace
ws = Workspace.from_config()
# Retrieve the dataset from Azure by its name
ds = Dataset.get_by_name(workspace=ws, name='NHL-Penalties-2020')
# Convert to a Pandas DataFrame
df = ds.to_pandas_dataframe()
Now, I’m not certain when it’d be helpful to do this, but you may find some reassurance that you can do this and that converting your data to datasets on Azure is not a one-way process.
Conclusion
Pandas DataFrames one of the more powerful ways of manipulating data outside of working in pure SQL and they can be a natural part of your data science and data analytics workflows. As a result, the ability to easily register a Pandas DataFrame in Azure is a key part of the Azure Machine Learning workflow for many data scientists.
Hopefully this article was helpful to you on your data science journey. Let me know what you’d like to cover next!

