Azure ML Studio: Getting Oriented with Azure Machine Learning
An introduction to Azure's machine learning offering for beginners and experts
Azure Machine Learning Studio (often shortened to ML Studio or AMLS) is Microsoft’s premier data science portal.
Here’s a sampling of some of the things ML Studio lets you do:
- Train machine learning models
- Evaluate trained model performance
- Launch new experiments in a variety of ways
- View the results of past experiments
- Deploy trained models as REST endpoints
- Monitor deployed models
- Track datasets and models
- Provision and manage compute resources
- Conduct data science experiments in online notebooks
Obviously, this is a pretty powerful application.
In this article we’re going to take a look around the application and get a closer look at the things it can do.
This content is also available in video form on YouTube
Getting to ML Studio
In order to get to ML Studio, you need to first have one set up. If you haven’t done that yet check out the tutorial on setting up a Machine Learning instance for more details.
Assuming you have an existing ML studio instance, you can get to Machine Learning studio in one of two ways:
- Finding your machine learning instance in the Azure portal and clicking on the “Launch studio” button on its overview page
- Navigating directly to ml.azure.com and selecting your machine learning instance.
Either one of these options should take you to your Azure Machine Learning Studio home screen.
Home Screen
The home screen allows you to quickly create a new Notebook, Automated ML Experiment, Designer experiment, Pipeline, Dataset, Compute instance, Training cluster, Datastore, Data labeling project, environment, or training job (currently in preview at the time of this writing). Each of these sections are covered elsewhere in this article in more detail.
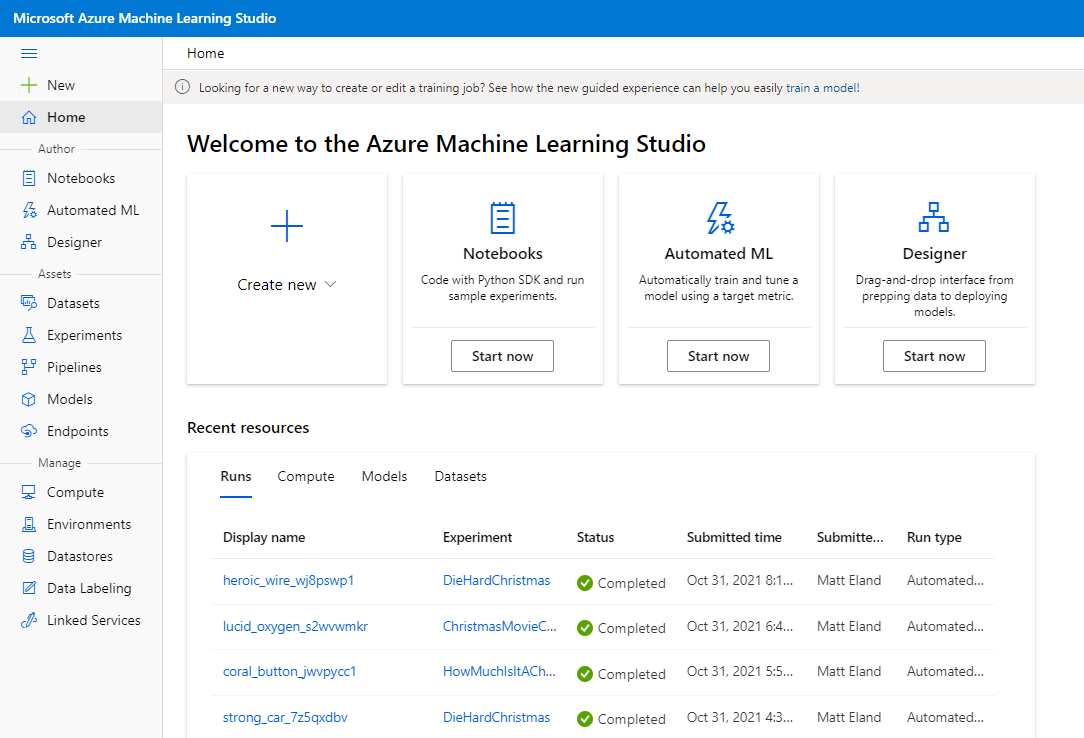
The home screen also lists the different runs, compute resources, models, and datasets that you have previously created and provides links to get more details on each one.
This effectively makes the home screen a very effective jumping off point for most things you might want to do in ML Studio.
Additionally, the bottom of the home page has a collection of links to helpful Microsoft Learn content and other resources to help you get started.
Navigation
The sidebar on the left is shared between all major pages and can be collapsed and expanded by pressing the three straight lines at the top of the sidebar.
The rest of this article will follow the order of items on the sidebar.
Author
The three authoring options are all built around creating new machine learning experiments, but they are aimed at users of different proficiency levels.
Notebooks
The notebook section allows you to run Jupyter notebooks on Azure using compute instances to power the execution of code in those notebooks.
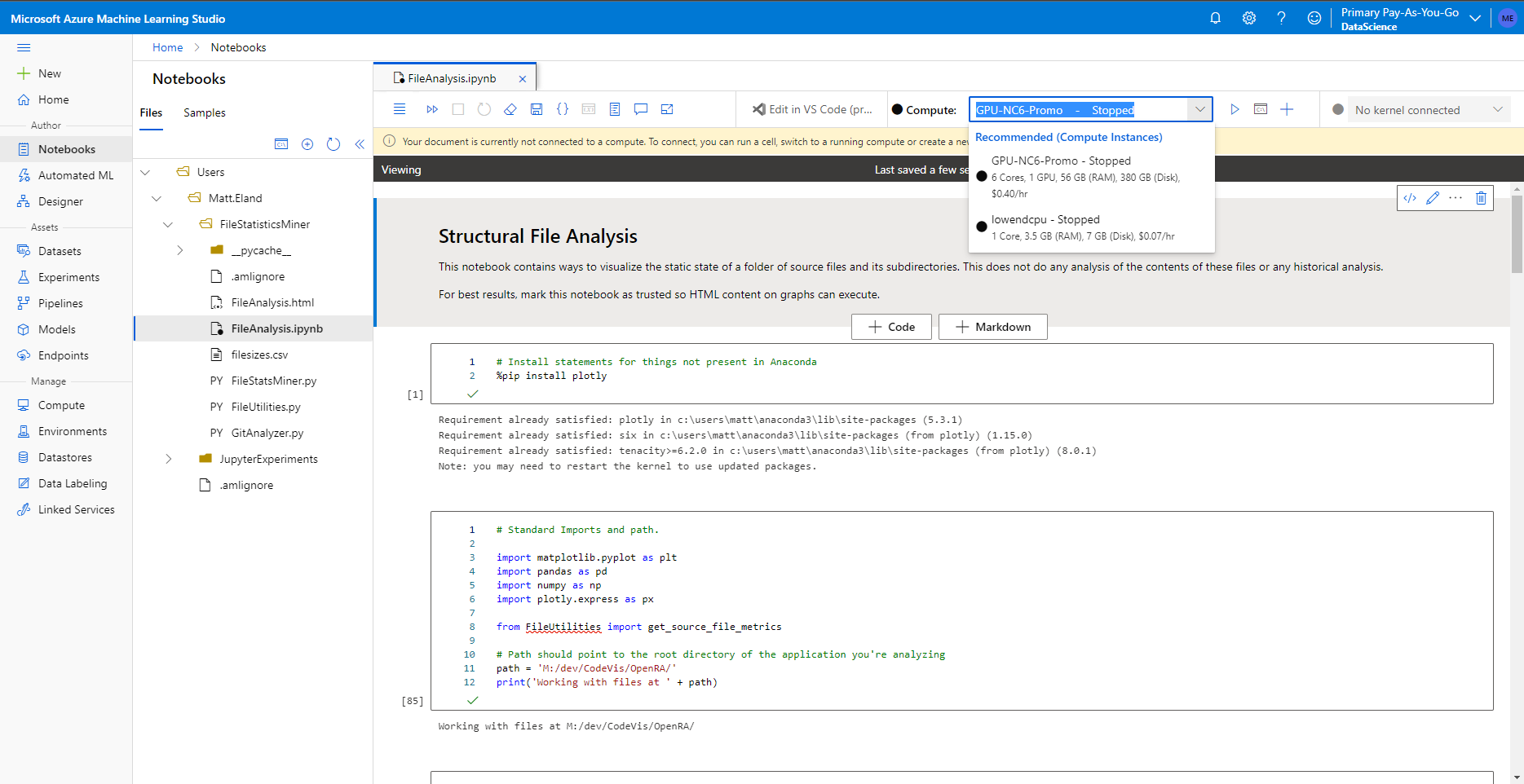
For those of you not familiar with Jupyter notebooks, these are interactive code environments that let you mix together blocks of Python code that can be executed by anyone with access to the notebook. The result of the last statement from each block of Python code is displayed for the user to see (along with the output of calls to print) which makes them ways of seeing intermediate results when you are transforming or visualizing data.
While Jupyter notebooks can be hosted on any machine via distributions like Anaconda, hosting your notebooks in the Azure environment allows you to more easily share them with other team members.
Learn More: Installing Anaconda and getting started with Jupyter Notebooks
Microsoft also offers the Azure SDK which allows for Python code to interact with ML Studio resources and experiments. By running the Azure SDK in the cloud, you simplify the process of authentication which makes it a little easier to get started with the SDK.
As a result, the Notebooks section of Azure Machine Learning Studio makes it helpful for anything from sharing interactive experiments with Python to cleaning data to creating and running actual machine learning experiments, making notebooks a viable option for data scientists familiar with code who would like to work in a collaborative online environment.
Automated ML
Automated ML, sometimes referred to as Auto ML for short, is a no-code way of automating machine learning experiments. With Automated ML you specify the dataset you want to use, what type of machine learning task you’re trying to accomplish, some optional parameters, and what compute resource you want to do the work.
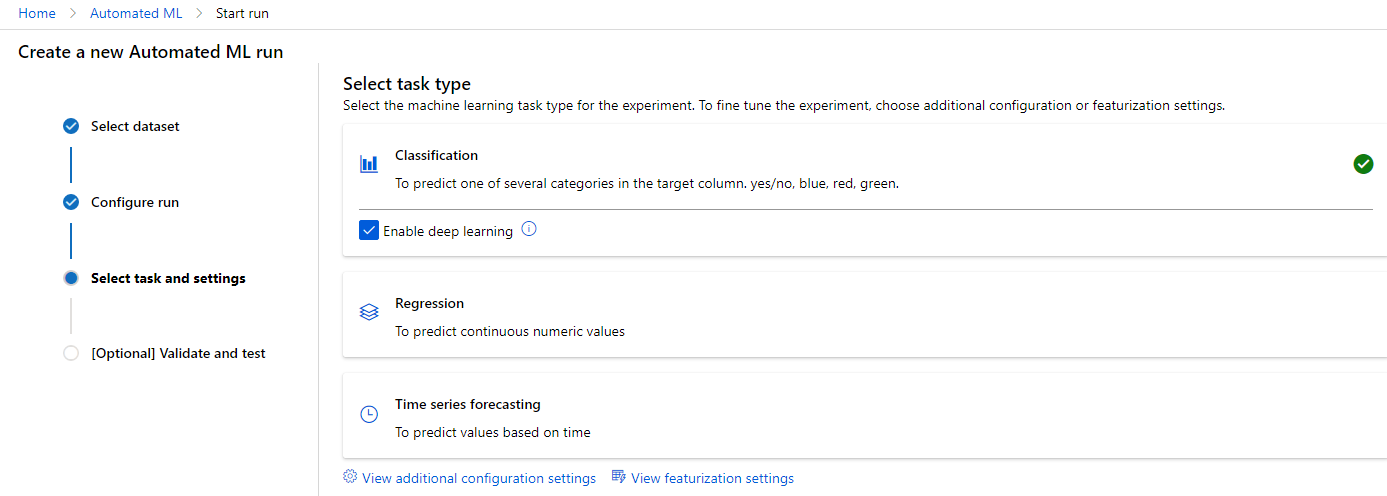
I make no exaggeration when I say that automated ML is one of my favorite features on all of Azure. Not only does this feature simplify machine learning tasks so that new data scientists can be useful while still learning various algorithms and pieces of code, but it’s also useful for experienced data scientists who might not think of using a specific algorithm or set of parameters.
Azure will launch a number of different runs and zero in on which algorithms and hyperparameters perform the best on the experiment. Experiments last until they are no longer improving after a sustained period of time or some “guard rails” are triggered such as model performance or a time limit have elapsed.
At the end, Azure presents you with the best performing model and you can evaluate its performance, algorithm, and hyperparameters.
You can then navigate in and get an explanation of what features this model chose about your dataset as well as detailed graphs of its performance.
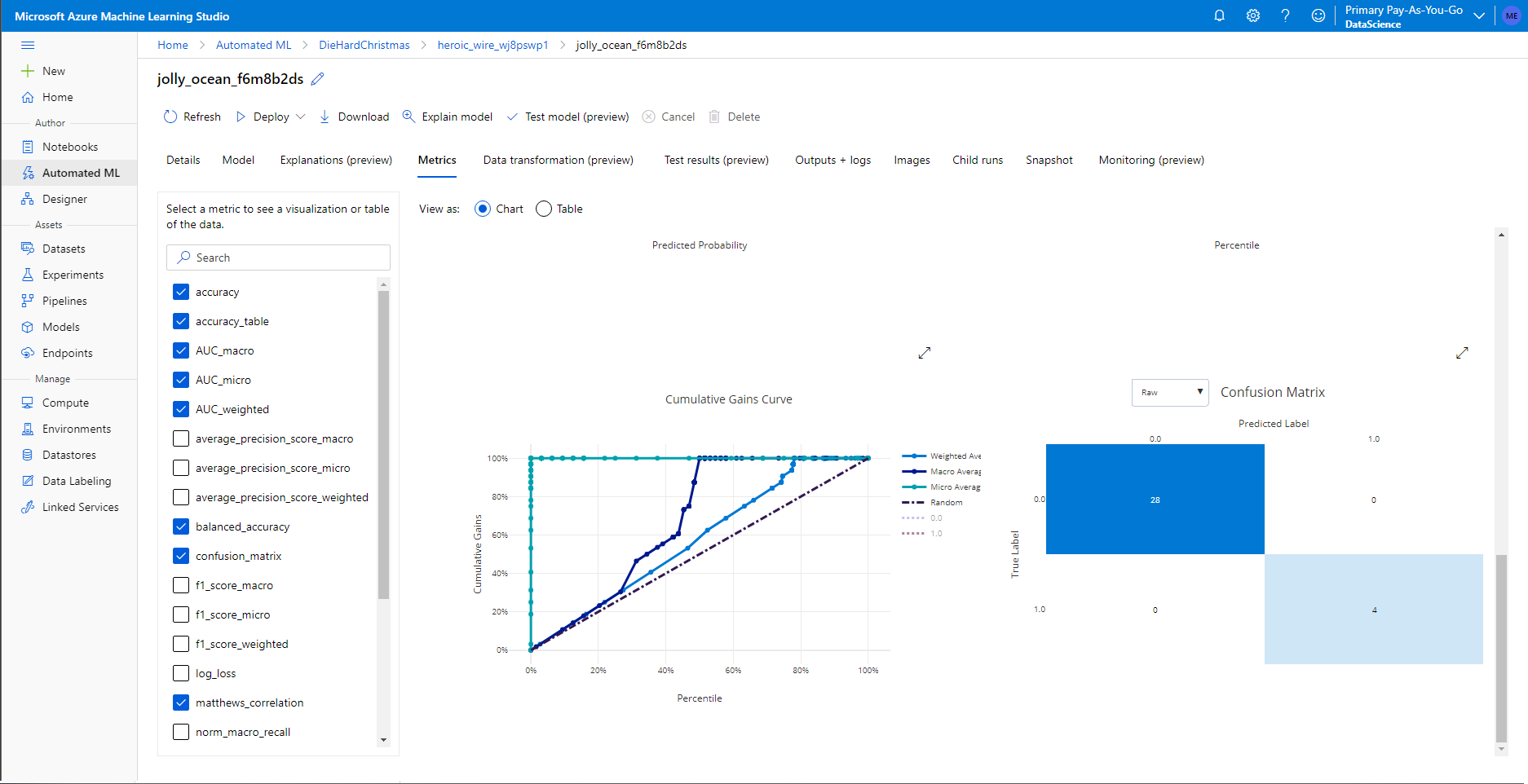
This greatly improves the Transparency of the generated models which helps you understand how the model is performing and may alert you to any bias.
Important note: While Azure will come up with the best algorithm it can, it is your responsibility as a data scientist to make sure that the data you are feeding Azure is accurate and useful and not likely to introduce any sort of bias to the solution. Additionally, you still need data science knowledge in order to be able to structure your experiment and evaluate the performance of the results. Azure just makes the rest of data science a bit easier.
Designer
If Automated ML is designed partially with the novice in mind, the designer is a step up from there. You are still in control, but you must now direct the major steps of a machine learning pipeline as Azure moves incoming data through various steps as it trains a model.
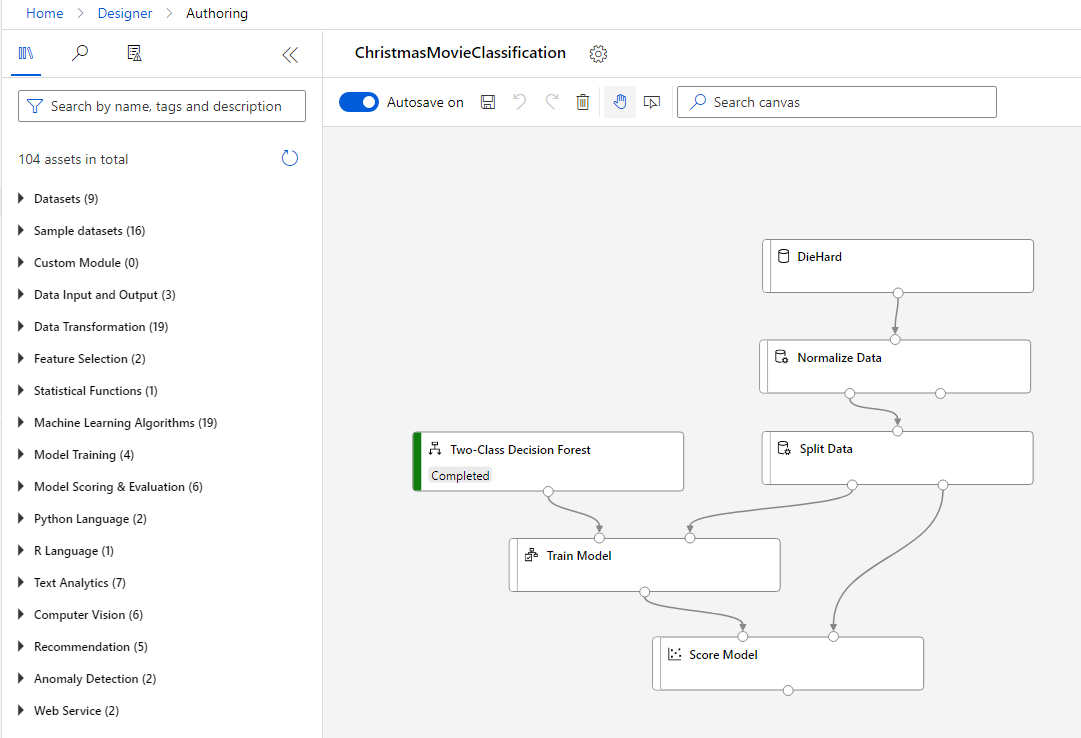
The designer is attractive to people who’d like to think at a higher level and don’t want to worry about specific Python or R code for executing standard tasks.
However, you do still need to know a lot of machine learning concepts as far as normalizing data, feature engineering, splitting data for training and validation, and various machine learning algorithms.
Additionally, it’s worth noting that there are code nodes for both Python and R code that you can include into a machine learning pipeline. These nodes allow you to execute custom code in a machine learning pipeline for certain steps while still taking advantage of the drag and drop and visual nature of the designer.
Assets
Okay, so now that we’re past the basics of running experiments, let’s take a look at some things that make experiments possible.
Datasets
First of all, datasets allow you to store different sources of data that machine learning runs can execute against.
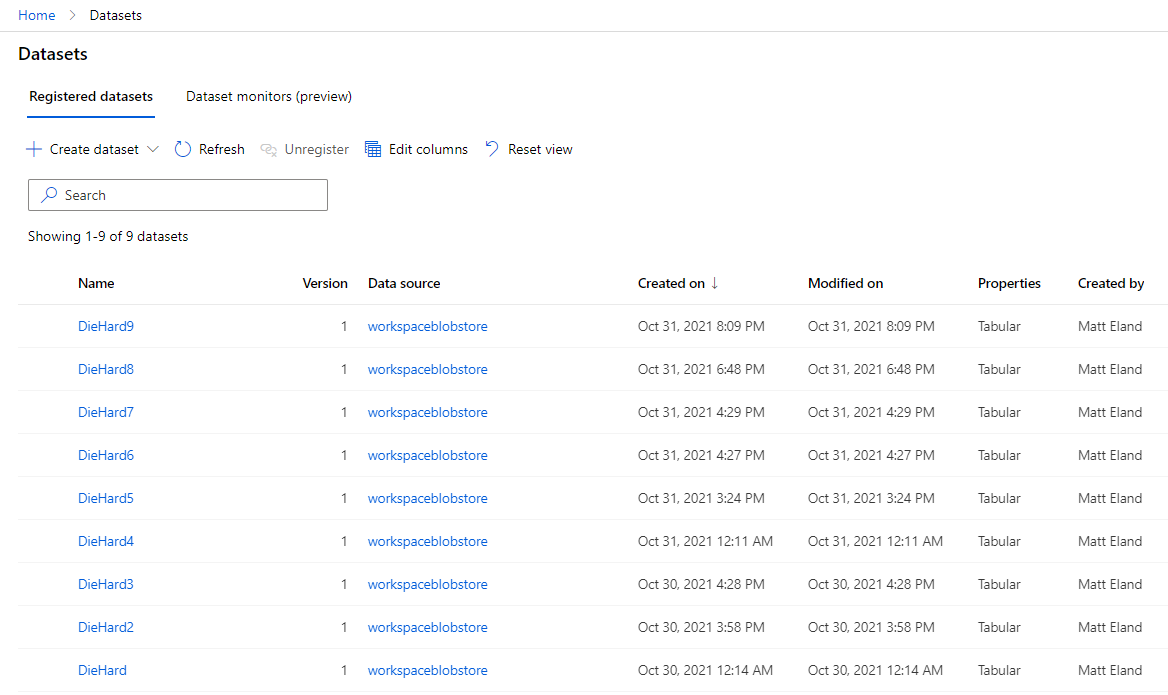
This allows you to add new copies of datasets and even version those datasets to track changes over various editions - a feature unfortunately not used in the screenshot above during a prior experiment.
Datasets allow you to explore that data and build a profile of it for analysis. In some cases this might lessen the need for exploratory data analysis (EDA) and visualization, but its main draw is the ability to quickly get basic information about columns in a dataset directly from ML Studio.
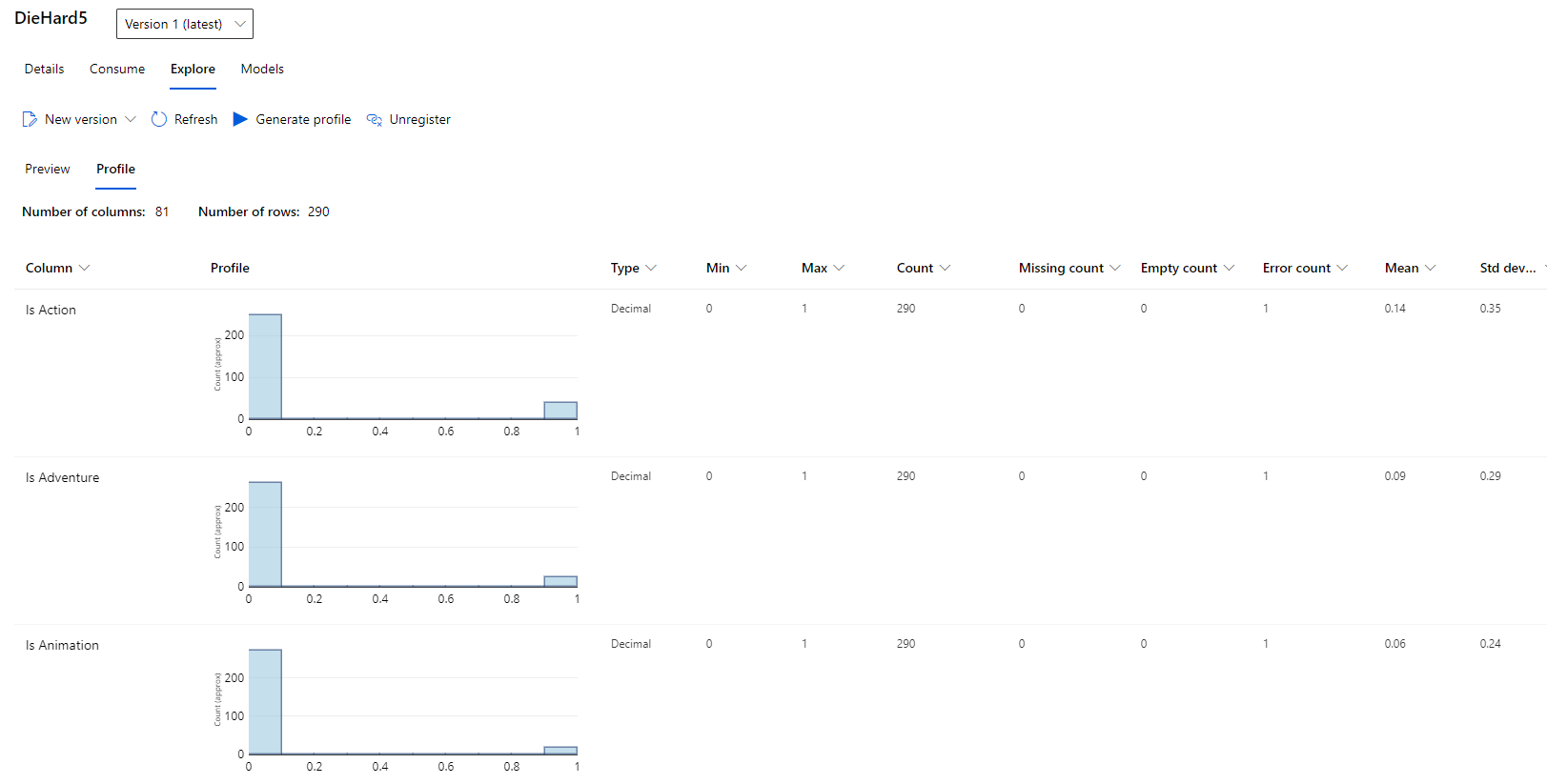
Azure is currently previewing the concept of a dataset monitor to monitor data collection and help detect data drift, but this feature is not covered in the scope of this article.
Experiments
Experiments in ML Studio are collections of one or more machine learning runs.
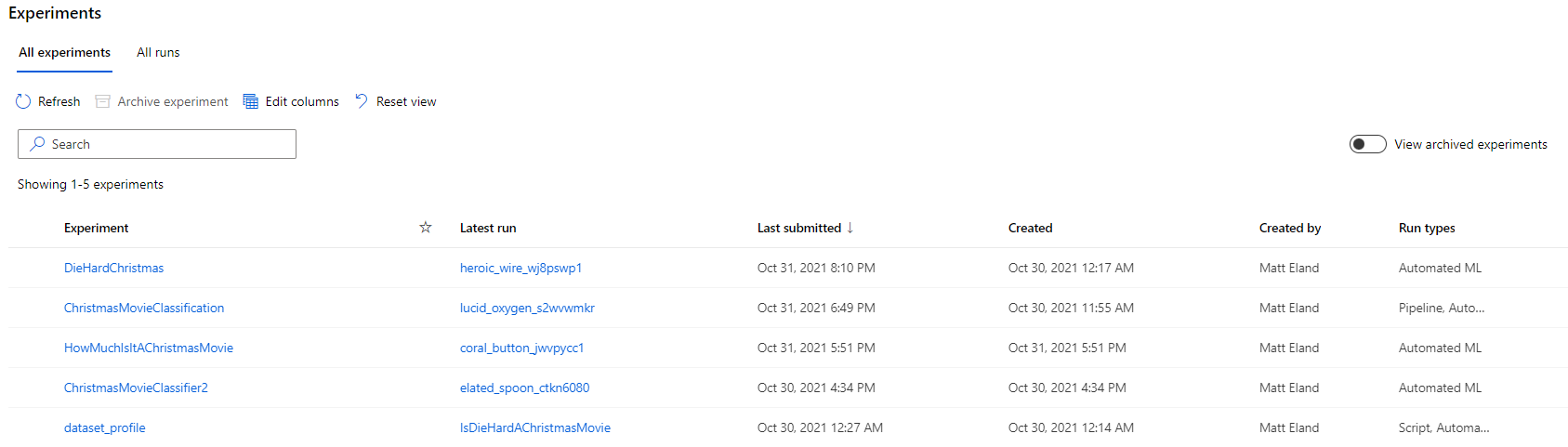
This allows you to track various runs and the performance of the best model in each run, which ultimately tells you if an experiment is still progressing or has reached a level of accuracy you view as acceptable.
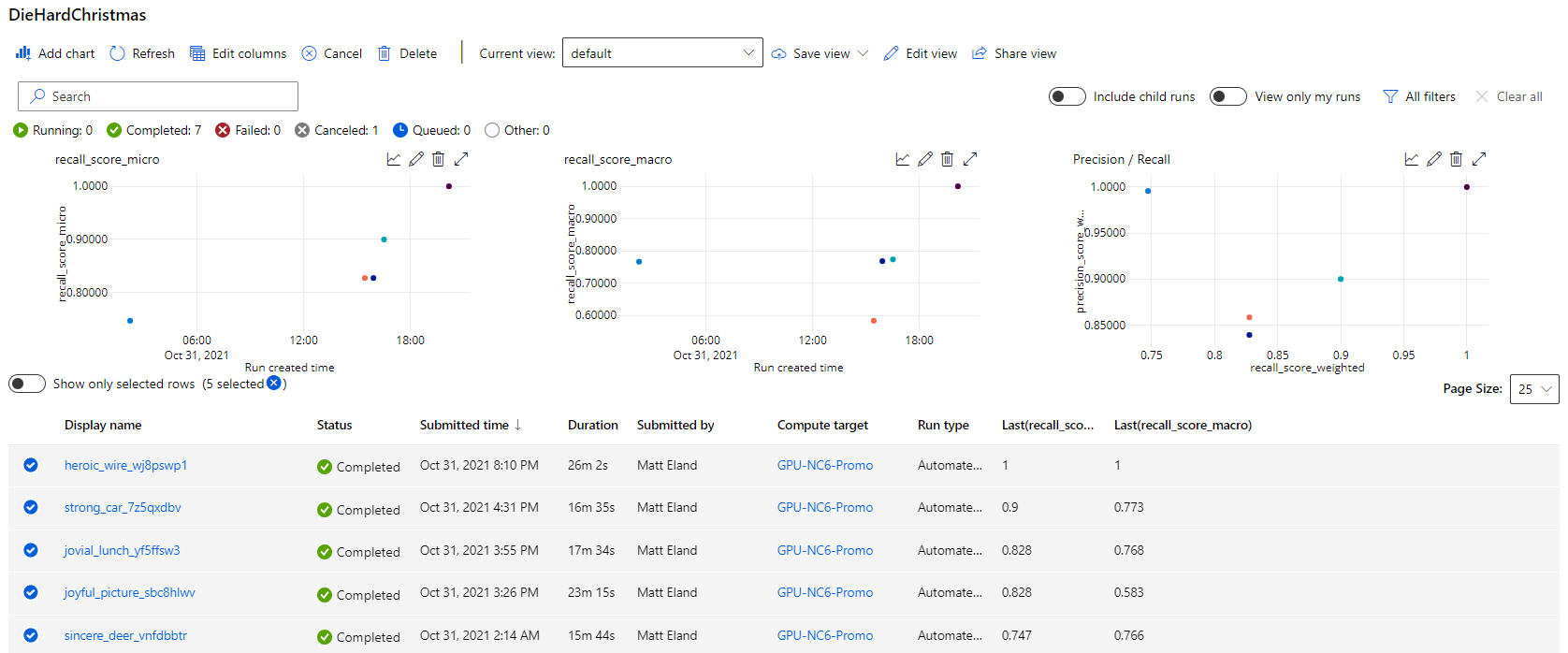
From here you can click on a given experiment to get more details on that experiment, including its duration, parameters, compute target, and high level information on its best model. More specific information on all evaluated models and any additional logged data are present in other tabs on this interface.
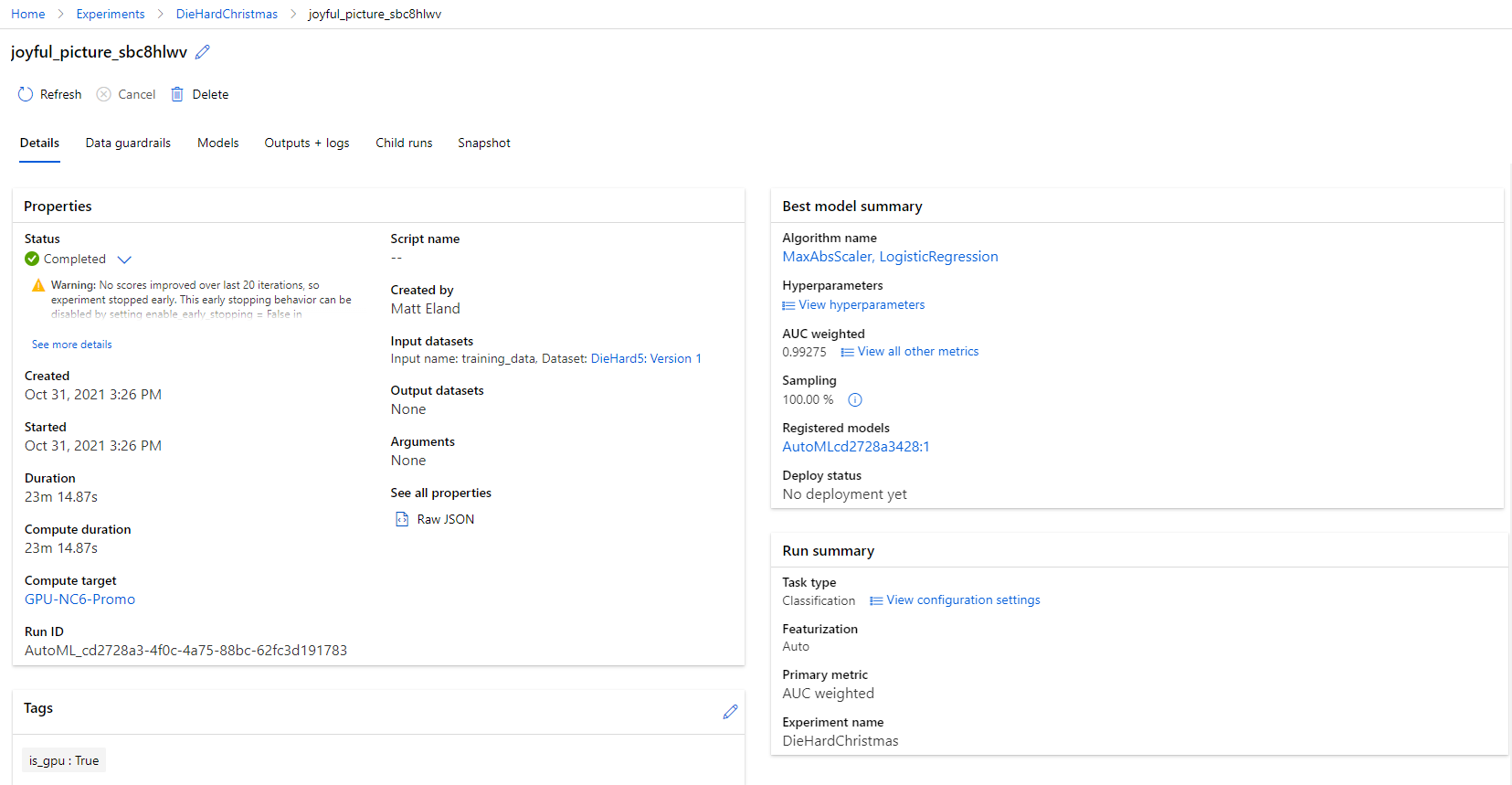
You can click on the best model from either the list of experiments or the experiment details page to go to the corresponding model page, which will be discussed shortly.
Pipelines
The Pipelines tab is a smaller one and exists to track historical runs in the Designer tab.
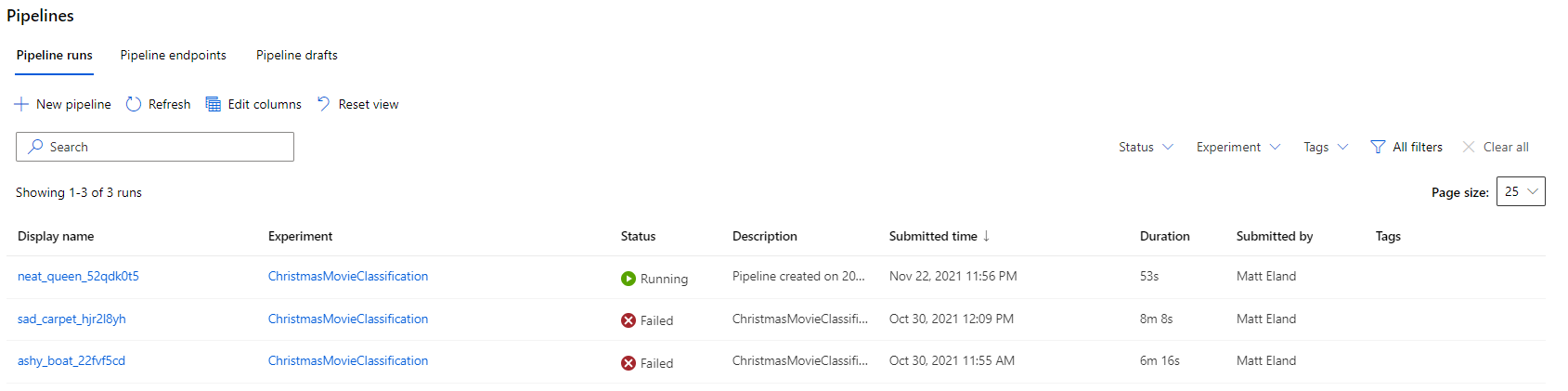
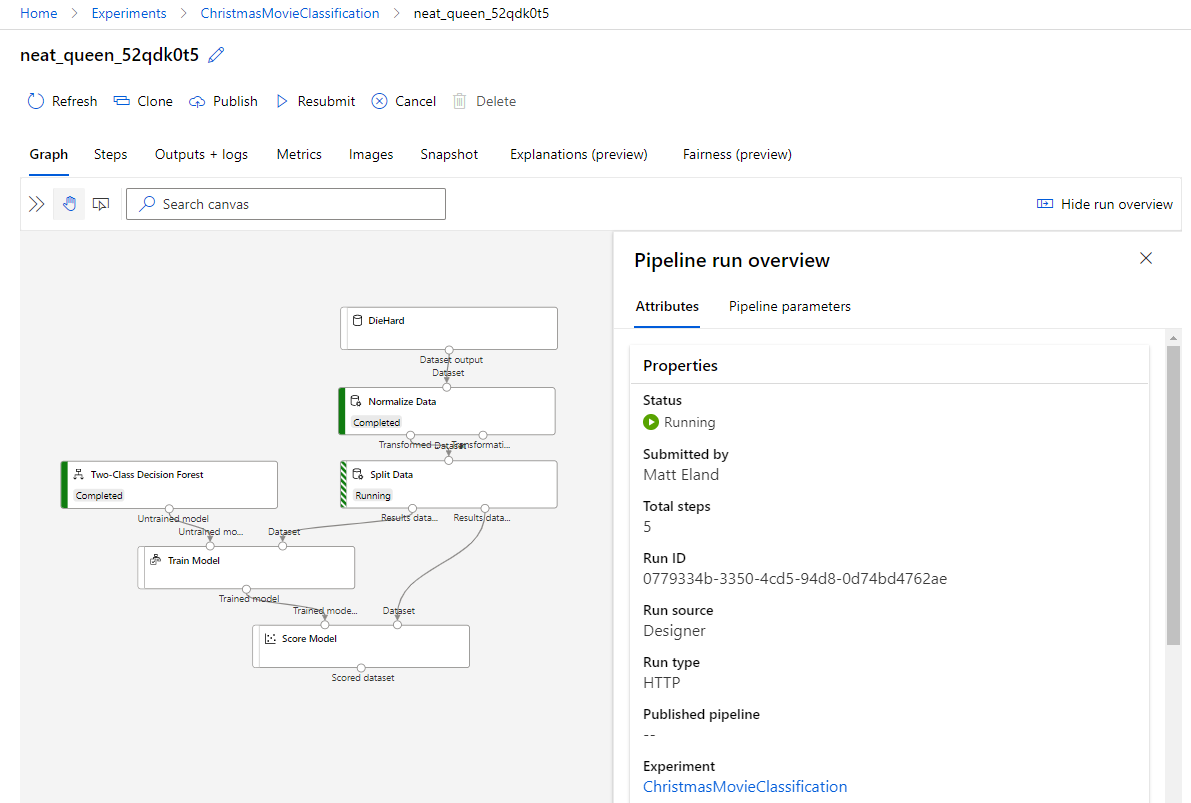
Clicking on any pipeline here will take you to the corresponding run in the designer view.
Models
The models view at first glance appears to just be a place to track your existing models and navigate into details for them.
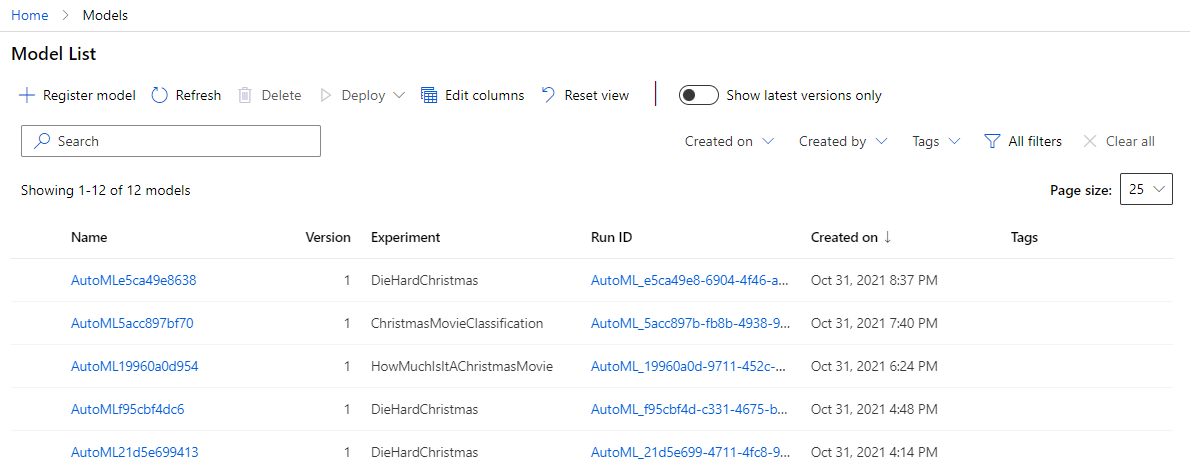
However, there’s more to this page than that. You can actually register models trained outside of ML Studio via TensorFlow, PyTorch, and many other frameworks. This allows Azure to track those models and you can refer to them at a later date.
From the model details page you can view details about that model including any artifacts that it generated. You can also deploy a model as an endpoint for real-time or batch evaluation so that other people can use the model you built.
If you’re not intending to deploy your model in the cloud, you can always download the model’s pickle (pkl) file and work with it from Python code elsewhere. Azure really does let you focus on the things you care about - whether that’s training or evaluation or deployment or monitoring of your machine learning solutions.
Endpoints
The endpoints view lists any endpoints you have previously created - whether they are currently online or not.
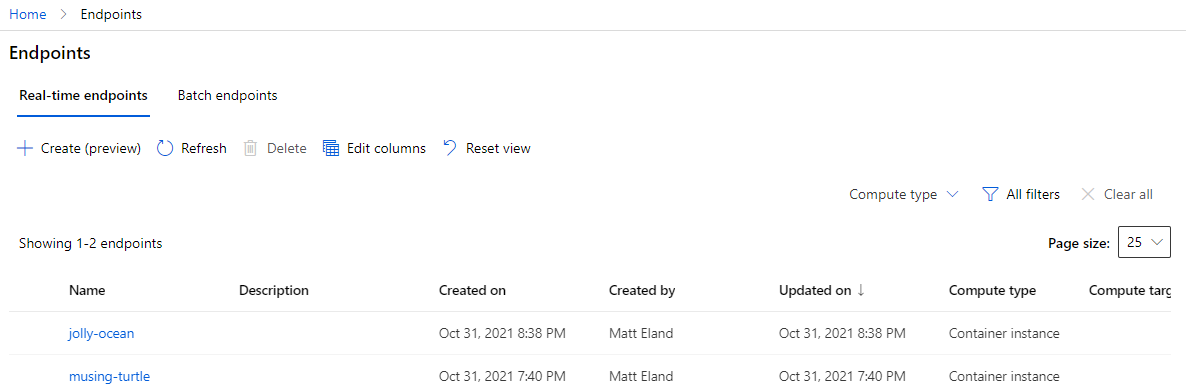
From there you can drill in to a specific endpoint and get information on its model, the REST endpoint it reacts to, any logs associated with it, and a swagger file to help applications communicate with it.
Manage
The manage series of tabs allows you to provision resources to support the rest of your ML studio needs.
Compute
The compute tab is mandatory for anyone wanting to run an experiment. This allows you to create and manage your compute instances, compute clusters, and inference clusters as well as allowing you to designate attached compute resources.
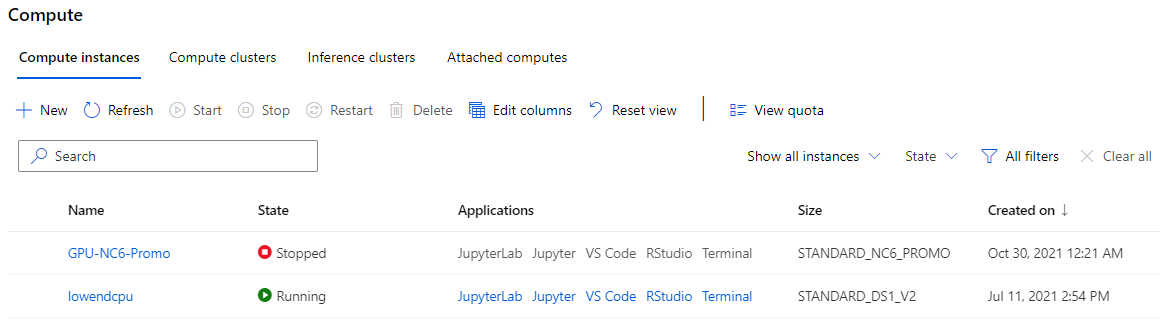
That’s a lot of terminology so let’s clarify a few terms here:
- Compute instances are individual compute resources that are primarily intended to be used for notebooks and small experiments. These instances also support applications such as Jupyter notebooks and VS Code so you can use them as temporary web-based development environments. These resources must be stopped and started in order to work.
- Compute clusters are scalable clusters of similar compute resources that can scale up and down as tasks come in needing their attention. These are used for model training and are intended for larger training tasks.
- Inference clusters are scalable clusters used to power deployed machine learning solutions. They cannot be used for training.
- Attached compute refers to resources defined in Azure outside of ML studio that can be used for machine learning tasks. Databricks, Virtual Machines, and HDInsight instances are all examples of attached compute. These resources are available as a compute target for model training.
If you are working with these resources, please understand that there is a cost to each one. Azure actually does a fantastic job of making that price per server tier visible to you as you are creating a server, but you are still responsible for starting and stopping compute instances to manage costs appropriately and responsible for choosing the most cost-effective resource for your task.
Note: See my article on the different types of compute resources in Azure Machine Learning for details on what all of these are and best practices to use with them.
I strongly encourage you to read Microsoft’s guidance on cost management with machine learning before creating your first compute or inference resources.
Note: If you want automated machine learning without Azure or without any expenses, you might also consider ML.NET which uses many of the same innovations but requires programming knowledge.
Additionally, I strongly recommend you create an automatic shutdown rule for any compute instance you create and set it to run daily at a time of your choosing. This will limit the costs you can accrue by failing to stop a running compute instance.
Environments
The environments view lists environmental configurations available for machine learning tasks. This feature is most relevant when using the ML SDK where you must specify environment requirements for any host running your experiment.
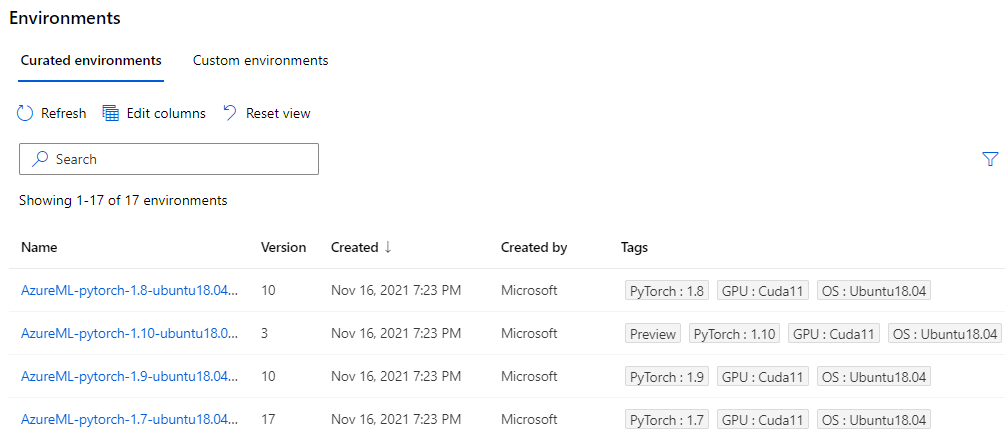
You can also upload your own configuration options in various formats for defining your own custom environment file, though that’s more of an advanced workflow.
Datastores
Datastores simplify accessing different sources of data via the SDK. They can be used to get data out of most of the data offerings on Azure including blob storage, Azure SQL, and Azure Data Lakes. See this article from Microsoft for more documentation on datastores.
Data Labeling
Data labeling projects can be used for image classification projects and are more of a part of Azure’s computer vision offerings than they are a part of the traditional machine learning tasks in ML Studio.
See Microsoft’s documentation for additional details on data labeling projects.
Linked Services
Linked Services allows you to link a ML Studio workspace to a Synapse Analytics workspace.
This is a more advanced feature that is currently in preview and will not be discussed in detail, but documentation exists that will help you learn more.
Next Steps
Okay, so that was a lot of content, but the central point I hope you get here is that you can do a lot with ML Studio.
ML Studio is built for cloud-based management of models and experiments. Using ML Studio you may choose to train your models using Azure compute resources, the designer and its pipelines, or the wonderful automated ML, but you are not required to do so. Additionally, ML Studio allows you to deploy trained models and monitor them over time, but this is not a core requirement for all users and Microsoft understands that.
Ultimately ML studio aims to meet the needs of a wide variety of teams with varying preferences, skills, experience, and comfort levels. Frankly, I think this is amazing and this is a huge reason as to why I’ve started writing recently on machine learning on Azure.
Over time I hope to produce more specialized content into aspects of ML Studio and the Azure ML SDK, but for now I have two recommendations for you as you look to learn more:
- Go through Microsoft Learn’s machine learning content and learn about the things that interest you
- Study for and take the Azure AI Fundamentals (AI-900) exam and get a more in-depth experiential knowledge of ML Studio.
I wish you the best and much luck on your machine learning adventures.

