
Understanding Reinforcement Learning
Encouraging organic discoveries through intelligent AI agents
I still remember the first time a computer surprised me. It was a simple moment playing a video game and the AI enemies managed to distract me on one side well enough for enemies to sneak up on me from the side and take me down. What truly struck me about the encounter was that it didn’t appear to be scripted, but rather appeared to be the result of AI agents making reasoned decisions about their environment and using those to their advantage.
This single moment from a gaming session cemented my love for AI and fostered a curiosity for finding ways that AI entities could pleasantly surprise and impress me with their solutions to problems.
In the decades following this encounter, what I have found is that reinforcement learning in a controlled environment is the best way of allowing AI agents to come up with surprising strategies and approaches to solve a problem in a way you might never have expected.
In this article we’ll explore what reinforcement learning is, what is can be used for, what it can’t be used for, some popular algorithms for reinforcement learning, and some tips for succeeding with a reinforcement learning project.
What is Reinforcement Learning?
Reinforcement learning is a branch of artificial intelligence that focuses on allowing AI agents to organically discover effective solutions to problems in constrained environments.
In a reinforcement learning scenario agents are given some sensory inputs about their world and the ability to act in various ways in that simulation. The simulation then provides a score on how well that particular agent did in that scenario after some fixed duration.
Over time, AI agents will experiment and discover the actions that maximize their scores based on the inputs received. As a result, future agents will emulate the success of prior agents but with small changes and experiments to see if their scores improve or decrease.
This results in a series of agents that progressively learn the actions and strategies that maximize their score within the simulation world.
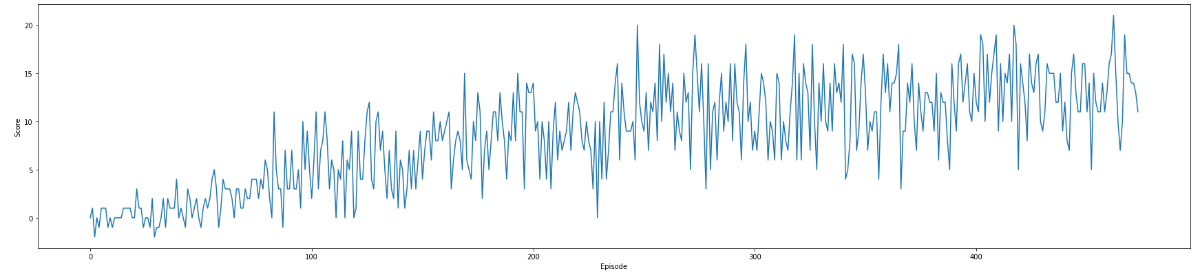
The score of a somewhat chaotic reinforcement learning algorithm gradually improving over time
At first glance, reinforcement learning appears to be an optimization strategy, much like a regression model in machine learning, but there are a few key differences:
- Regression models are an example of supervised learning where we know historical approaches and their results.
- Reinforcement learning does not require or use historical data, but it is not exactly unsupervised learning like a clustering model. Instead reinforcement learning can be thought of as a form of semi-supervised learning.
- Regression models excel at converting individual observations into an equation or model we can use to predict new models
- Reinforcement learning is built for discovering new approaches to solving problems, including approaches that have never been considered or tried before by a human
- Regression models are trained by memorizing trends in large amounts of data. This takes time, but the amount of time is typically fixed.
- Reinforcement learning is iterative in nature with the best solution gradually improving over time until an optimal strategy is discovered or the training process is ended
So we see that reinforcement learning is different than traditional machine learning. Both machine learning and reinforcement learning train solutions that can be used to make decisions in new scenarios. However, traditional machine learning requires historical data while reinforcement learning does not. Traditional machine learning typically has a fixed duration for training while reinforcement learning is done iteratively until you are satisfied with the performance of the best performing agent.
The key advantage of reinforcement learning is that it does not have human preconceptions about how to solve problems and may come up with innovative and creative solutions you never considered. In fact, some of my favorite moments programming AI solutions have come from seeing reinforcement learning solutions find solutions to problems I never considered. I’ve even occasionally seen reinforcement learning solve problems I wasn’t sure were even solvable.
When to Use Reinforcement Learning
Given these differences between machine learning and reinforcement learning, when is it appropriate to use reinforcement learning in a solution?
I would consider reinforcement learning if:
- The optimal strategy for solving a problem is not known or you want to see if better strategies exist than previously known ones
- You can adequately simulate the environment your simulation will be running
- You have a way of giving a numerical score to solutions, including partial solutions
- You have time to simulate thousands of strategies, including poor performing strategies
Conversely, you should avoid reinforcement learning if:
- The optimal solution to the problem you’re trying to solve is already known
- The problem does not lend itself well to giving a numerical score to partially working versions
- The simulation space is not known or is hard to accurately emulate
- Poorly performing agents will have a direct negative effect on others during the training process
Clearly reinforcement learning is not a universal solution, but it does solve some key problems better than anything else. In particular, reinforcement learning performs particularly well for robotics and game development tasks. We’ll explore those in a little more detail next.
Reinforcement Learning in Robotics
In robotics, reinforcement learning is used for controlling the various motors available to the robot to balance the robot and help it navigate an environment in a stable, efficient, and reliable manner. Using reinforcement learning, robots can learn an optimal pattern for moving their various joints to balance, walk, run, grasp objects, and even jump.
While reinforcement learning is helpful for bipedal robots that are human-like in nature, it is perhaps more valuable when working with robots with multiple legs or body configurations that don’t mimic those found in nature. Examples of these might include arms in an assembly line, robots with unusual weight distributions, backwards joints, or an unusual number of limbs.
With robots not strictly modelled after natural creatures we don’t have something to observe and mimic and so we need to effectively guess at the optimal way of moving these robots around would be. As a result, reinforcement learning can help discover ways of moving robots that maximize stability, minimize the energy needed to move, and effectively and safely help the robot accomplish its tasks.
Reinforcement Learning in Gaming
Games can use reinforcement learning to train artificial intelligence agents to carry out goals in the game environment.
Using reinforcement learning, AI agents can try a variety of strategies and discover the optimally performing ones in the game environment. This allows AI agents to discover game rules in an organic way, such as learning that fire will harm them, but pushing attackers into fire helps them get away.
By automating reinforcement learning, AI agents can be retrained if major parameters in the game change during development. This allows the AI to evolve as game parameters and rules change. Contrast this to traditional AI approaches where a strategy that was hard-coded in an AI early on might lose effectiveness as the game moves closer to its ship date.
Reinforcement learning can either take place offline during development of the game or in response to the player interacting with the game.
This later approach is interesting because it would allow AI agents to adapt to player strategies as the player plays the game. However, there are a few key problems with this:
- In reinforcement learning, many good and bad strategies are tried on the way to developing an optimal strategy. This means a player would encounter many bad AI implementations during the training process.
- The training process often takes a significant period of time. This means that for the player to observe any improvement in AI agents it would need to take a significant amount of time, though this can be mitigated by training AI agents across all players playing the game.
For these reasons, reinforcement learning can be more reliable when using it to pre-train AI agents that can be rigorously tested and then released in their final trained forms.
Finally, reinforcement learning is almost universally used when building an AI to play games, particularly video games. These systems either look at a representation of the game world (such as what is near the player) or at the raw pixels of the screen.
Other Applications
While robotics and gaming are two of the more common applications of reinforcement learning, they are applicable to any scenario where you can adequately model the simulation space and do not know the optimal solution to a problem.
Reinforcement learning is currently being used or considered for many different applications and industries including:
- Structural engineering to design optimal structures to resist outside forces
- Software engineering to autonomously grow algorithms to accomplish a given goal
- Civil engineering and traffic management
- Manufacturing and warehouse robotics control
Let’s shift gears and look at a specific reinforcement learning scenario as an example.
A Sample Reinforcement Learning Scenario
Let’s illustrate machine learning with a story from my first foray into reinforcement learning.
I wanted to see if I could train a simulated squirrel to find an acorn in a simple game environment and take it back to the nearest tree. Also in the simulation was a rabbit that wandered randomly and a dog that remained stationary.
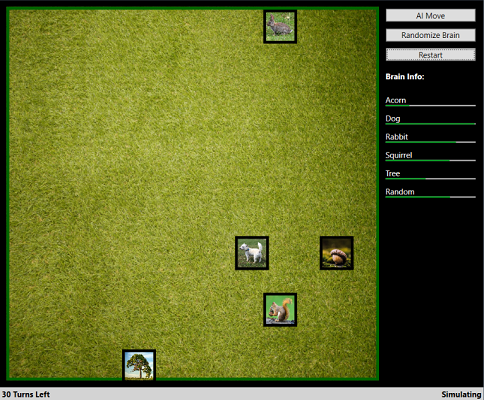
However, if the squirrel or rabbit came close to the dog, the dog would eat them. I coded the simulation to end in a win if the squirrel got the acorn and then returned to the tree and end in a loss if the squirrel was eaten by the dog or failed to get the acorn and return to the tree within a fixed time limit.
This set of rules gave me a consistent set of simulation rules, a way of allowing the squirrel to move around the world, and information about the game world that I could send on to the reinforcement learning agent.
I still needed to provide one more piece of information to the reinforcement learning training process: a way of scoring how well a potential solution performed.
Grading Simulated Squirrels
While knowing that a squirrel either won or lost was helpful, I needed to be able to provide a score so that the reinforcement learning algorithm could evaluate different solutions against each other and trend towards more optimal approaches over time until it found a solution that could consistently solve the simulation world.
What I chose to do was give positive and negative reinforcement for certain actions. For example, my rules were something like the following:
- If a squirrel gets the acorn, that agent is awarded 100 points
- If a squirrel with the acorn returns to the tree, they win and get 500 points
- If the squirrel wins, they get bonus points for the amount of time remaining (encouraging fast solutions)
- If a squirrel is killed by the dog, they are penalized 50 points
- If a squirrel loses (either due to time or from being killed) they are rewarded for the amount of time they were alive
The Resulting Agent
What I found was that this combination of rewards and penalties allowed a reinforcement learning solution to progressively find more optimal strategies until it converged on a winning solution.
- The very first squirrels stayed put because that minimized their chances of wandering into the dog.
- A little later, squirrels discovered that if they followed the rabbit around they would often stumble into the acorn and its additional reward
- Later squirrels learned to ignore the rabbit entirely and just make their way towards the acorn
- Finally, squirrels would discovered that once they had the acorn, the tree would generate a lot more points for them and they should go there.
- While these squirrels technically won the simulation, additional training time allowed squirrels to figure out that they should avoid the dog as well.

So here, reinforcement learning allowed squirrels to navigate through their world based on the proximity to things the squirrels found desirable and undesirable.
Emergent Behavior through Reinforcement Learning
At this point in my experiment, I had proved that reinforcement learning was viable for generating good strategies for an AI agent, but I wanted to see if it could surprise me, so I modified the scoring algorithm to give the agent an extreme amount of bonus points if the rabbit died.
Remember that my simulation did not allow squirrels to attack anything or interact with rabbits in any way, but I ran the training process again and after a period of time reinforcement learning solved this problem.
This experiment has yielded two different solutions to this problem.
The first solution had squirrels get their acorn and then wait until the rabbit wandered randomly into the dog before finishing the simulation.

Additionally, I’ve also observed some squirrels learning that if they follow rabbits around on the opposite side of the dog, they could gradually “herd” the rabbits towards the dog by removing movement options away from the dog and gradually nudging the rabbits towards danger.

Important note: no animals were harmed in the creation of this article
In this example application, reinforcement learning was able to find a solution to a problem, but also find several unexpected solutions through emergent behavior that the programmer didn’t even consider possible when coding the simulation.
Types of Reinforcement Learning
Before we close with a discussion of best practices for succeeding with reinforcement projects, let’s talk about the two major types of reinforcement learning: episodic and continuous.
Episodic reinforcement learning occurs over a given episode. This may be a fixed duration of time or some number of turns in a turn-based game. The key factor here is that an episode has a clear beginning and ending. In episodic learning, no learning happens until the episode has completed and can be scored at the end.
Continuous reinforcement learning occurs constantly and without any interruption. The results of continuous learning are constantly being incorporated into improving the performance of the agent. This also means that you must be able to give a score to the actor at any moment that relates only to its recent actions. Continuous learning is more rare and can be harder to implement than episodic learning, but it also allows for faster convergence on an optimal solution.
Reinforcement Learning Algorithms
Reinforcement learning is not one specific algorithm but rather a family of related algorithms all trying to solve similar problems.
The mathematics and specific implementations of each of these algorithms is outside the scope of this article, but here are some key algorithms in the reinforcement learning world:
- Monte Carlo Method a randomized method for converging on a solution without an initial bias
- Q-Learning an algorithm designed to use well-performing past strategies while exploring new ones at random
- Deep Reinforcement Learning not a specific algorithm, but a flavor of algorithms that use complex neural networks and back-propagation to reward well-performing algorithms
- Actor-critic algorithms pair a policy actor that governs behavior with a critic evaluator that grades the effectiveness of the policy
- Genetic Algorithms emulate the evolution of genes by having the best performing agents generate offspring by combining their genes using crossover and mutation
All of these algorithms work to experiment with the simulation space and gradually optimize towards the most effective solution.
It is worth noting that a number of of reinforcement learning algorithms only work with episodic reinforcement learning. Monte Carlo and genetic algorithms share these restrictions.
Additionally, a number of these algorithms have parameters to them that can make or break their effectiveness during training.
When working with reinforcement learning you may need to tweak a few parameters including the following:
- Learning Rate how much the algorithm adjusts in response to being right or wrong. High values can speed up learning at first, but resist finding the exact maximum value.
- Decay how quickly the learning rate reduces over time. Decay allows for a higher initial learning rate to find an optimal general area and then a lower learning rate later on to find an exact optimal solution.
- Network Structure for neural nets. Specifically, you’ll need to play with the number of hidden layers and the number of neurons in each hidden layer. Larger neural nets can have more complex solutions but take longer to converge on a solution.
The exact parameters will vary based on the reinforcement learning algorithm you selected, but expect to do some iterative tweaking to the setup of your training process before you converge on a good result.
Succeeding With Reinforcement Learning Projects
Now that we’ve covered what reinforcement learning algorithms are and how they work, lets wrap up with a few tips for succeeding in reinforcement learning projects.
Be okay with Failure
First, be sure you’re okay with the idea of failure. Your candidate agents will fail a lot during training. This is part of the learning process, but you may see a significant amount of time without meaningful progress towards your goal.
You’re going to find yourself spending more time than you think tweaking the parameters to your training process and nudging the reinforcement learning process in a good direction. This is somewhat normal.
Occasionally you’ll find that you thought reinforcement learning could adequately solve a problem you’re facing and the results are underwhelming or you simply cannot converge on a solution at all. In these cases you may need to confirm that the problem is indeed solvable, and solvable with the information you’re providing to your agent.
One final note on this: I do strongly recommend you write tests around the code that sends sensory input to your agents. Bugs in this code can completely invalidate the entire training process by giving your agents incorrect, noisy, or misleading information. I recall a particular project I worked on where a simple mistake involving some of the sensory information for an agent being incorrect led to a week of failed model training. Once that bug was identified with a unit test, reinforcement learning succeeded soon afterwards.
The Scoring Algorithm
The quality of your scoring algorithm matters more than which reinforcement learning algorithm you choose.
A good scoring algorithm should be able to:
- Provide bad agents negative feedback in the form of negative or low scores
- Provide good agents with positive reinforcement
- Help agents identify progress towards a good solution by giving incremental rewards for progress towards the overall goal
- Be able to rank different agents based on their performance
Bad algorithms only give rewards when the task is nearly or fully accomplished. These algorithms do not allow the training process to discover that it is getting closer to a solution which can delay or prevent a solution from being reached.
Using Reinforcement Learning Incorrectly
While reinforcement learning can seem incredibly powerful and almost magical when it works, it is not a solution for every problem.
You may want to avoid reinforcement learning if the problems you’re trying to solve lend themselves well to a linear relationship, you have a large amount of historical data to use for training a machine learning model, or you cannot accurately simulate the solution space or grade progress towards a full solution.
Reinforcement learning is one of many tools in a data scientist or AI engineer’s toolkit and that tool is very good at one thing: finding organic solutions to problems through structured experimentation without historical data.
That being said, when reinforcement learning works, it can surprise and delight users and even yield new discoveries through emergent strategies trained agents discover and employ to solve their problems.
Conclusion
In summary, if you want an AI agent that intelligently learns its environment, can discover optimal strategies, and even has the potential to surprise you with its innovations, reinforcement learning is something you should investigate.
While there are many different algorithms for reinforcement learning, all work by exploring the problem space, experimenting, generating a numerical score for various attempts, and then evolving towards things that performed well.
Some algorithms may have tendencies to converge more quickly on your solution while others may be easier to explain to others, but even more important than the specific type of reinforcement learning you choose is the scoring algorithm you employ.
My recommendation is that you pick a small starter project to get used to the ins and outs of reinforcement learning and how it works for a small problem. This should give you adequate experience to understand the obstacles you’ll face as you scale up to more challenging and complex environments.
If you’d like to learn more about reinforcement learning or play with a number of samples in controlled environments, I highly recommend you look at the documentation for OpenAI’s Gym library and particularly the basic usage page. OpenAI’s Gym provides a standardized environment for performing reinforcement learning on classic Atari games and a few other platforms and should be an educational resource. If you’d like a more detailed example, check out this tutorial on Paperspace’s blog.
Regardless of what path you take, I hope reinforcement learning can pleasantly surprise you and show you how AI can be much more than machine learning and how reinforcement learning can help you and your team discover surprising new strategies and approaches to the problems you’re facing.

