
Bulk Text Analytics with Azure AI Language
Batch Natural Language Processing tasks in C# in 1 call
This article is my entry as part of C# Advent 2023. Visit CSAdvent.Christmas more articles in the series by other authors.
Azure AI Language Capabilities
In 2022 I wrote a series of articles on the various language capabilities in Azure AI Services (which was called Azure Cognitive Services at the time). In these articles I highlighted capabilities like:
While the natural language processing capabilities of Azure are impressive, one consistent gripe I had was that Azure didn’t offer a centralized API that could perform all of these tasks in a single operation.
I’m happy to share that Azure AI Services now has this capability.
In this article, I’ll detail how to make a single call to Azure AI Language services to perform multiple natural language processing (NLP) tasks.
Getting our Key and Endpoint
In order to use Azure’s text analytics libraries you will need the endpoint URL and one of the two active keys for either an Azure AI services resource or an Azure AI Language resource.
These values can be found in the keys and endpoint blade of the appropriate resource as shown here:
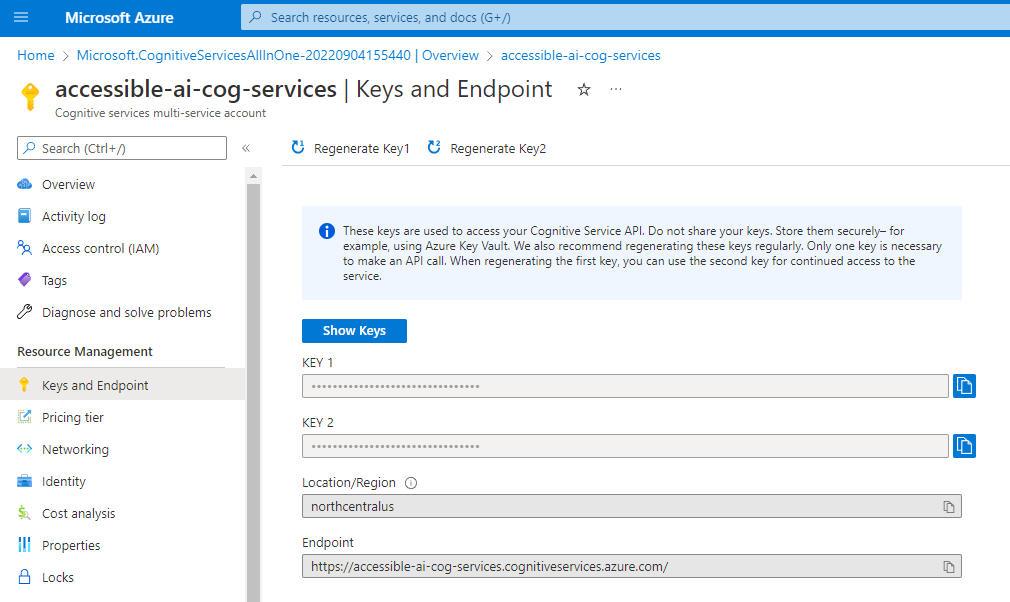
With these pieces of information we’ll be able to connect to our Azure resources from code.
Referencing the Azure AI TextAnalytics Library
While Microsoft makes its SDKs for interacting with AI services available in a variety of languages, I’ll be focusing on the .NET SDK in this article and using C# code.
To work with the Azure AI Language features we’ll first need to add a NuGet package reference to Microsoft.AI.TextAnalytics.
Next we’ll need to add using statements for the Azure and Azure.AI.TextAnalytics namespaces as shown here:
using Azure;
using Azure.AI.TextAnalytics;
With this complete, we’ll be able to modify any method to authenticate with Azure by creating a TextAnalyticsClient object.
The TextAnalyticsClient requires an endpoint in Uri form and an AzureKeyCredential, which can be provided by instantiating those objects as shown here:
public async Task AnalyzeTextAsync(string endpoint, string key)
{
Uri endpointUri = new(endpoint);
AzureKeyCredential credential = new(key);
TextAnalyticsClient client = new(endpointUri, credential);
Here we assume that endpoint and key hold values from those settings from Azure.
Caution: This is an opportune moment for the obligatory caution: your keys and endpoint are sensitive information and should not be stored in source control. If other people have access to these values they will be able to make authenticated analysis calls using your resources which you will be billed for.
With a TextAnalyticsClient in hand, we’re now ready to analyze some text.
Analyzing text with Azure AI Language and .NET
First, let’s see the text that we’ll be analyzing using an excerpt from A Christmas Carol by Charles Dickens:
Scrooge was at first inclined to be surprised that the Spirit should attach importance to conversations apparently so trivial; but feeling assured that they must have some hidden purpose, he set himself to consider what it was likely to be. They could scarcely be supposed to have any bearing on the death of Jacob, his old partner, for that was Past, and this Ghost’s province was the Future. Nor could he think of any one immediately connected with himself, to whom he could apply them. But nothing doubting that to whomsoever they applied they had some latent moral for his own improvement, he resolved to treasure up every word he heard, and everything he saw; and especially to observe the shadow of himself when it appeared. For he had an expectation that the conduct of his future self would give him the clue he missed, and would render the solution of these riddles easy.
Next, we’ll define the set of analysis actions we’ll be taking against this text. We do this by declaring a TextAnalyticsActions object and populating properties with lists of actions to perform:
TextAnalyticsActions actions = new()
{
AnalyzeSentimentActions = new List<AnalyzeSentimentAction>() { new() },
AbstractiveSummarizeActions = new List<AbstractiveSummarizeAction>() { new() },
ExtractiveSummarizeActions = new List<ExtractiveSummarizeAction>() { new() },
ExtractKeyPhrasesActions = new List<ExtractKeyPhrasesAction>() { new() },
RecognizeEntitiesActions = new List<RecognizeEntitiesAction>() { new() },
RecognizeLinkedEntitiesActions = new List<RecognizeLinkedEntitiesAction>() { new() },
RecognizePiiEntitiesActions = new List<RecognizePiiEntitiesAction>() { new() },
AnalyzeHealthcareEntitiesActions = new List<AnalyzeHealthcareEntitiesAction>() { new() },
};
We’ll talk about each one of these capabilities briefly as we cover the results, but at a high level what we want to do is:
- Perform sentiment analysis to determine if the text is positive, negative, neutral, or mixed.
- Summarize the text using abstractive summarization which summarizes the text with new text generated by a large language model (LLM).
- Summarize the text using extractive summarization which summarizes the text by extracting key sentences or parts of sentences to convey the overall meaning.
- Extract key phrases of interest from the text document.
- Perform entity recognition and linked entity recognition to determine the major objects, places, people, and concepts the document discusses.
- Recognize any personally identifiable information (PII) present in the document for potential redaction.
- Analyze the text for healthcare specific topics such as treatment plans or medications.
With these actions declared, we need to to provide a list of text documents to analyze. This can be either an IEnumerable of strings representing different text to analyze, or TextDocumentInput objects which contain both an identifier and a string.
The TextDocumentInput approach is helpful when you want to analyze multiple text documents at the same time, but it’s less helpful when you are only analyzing a single piece of text.
We’ll declare our text documents using a string array with our single string from earlier:
const string documentText = "Scrooge was at first inclined ..."; // truncated for brevity of example
string[] documents = [documentText];
With our documents collection, we can now call out to Azure using the TextAnalyticsClient from earlier:
AnalyzeActionsOperation operation = await _client.AnalyzeActionsAsync(WaitUntil.Completed, documents, actions);
This tells Azure to begin the analysis process of our documents. Notice that we provide not just the documents to analyze and the actions to take while analyzing them, but also a WaitUntil value that will either be Started or Completed.
Since we’re working with a single small piece of text, waiting until the analysis is fully complete makes sense, but you can also begin the analysis and use the resulting AnalyzeActionsOperation object to monitor the completion of the various analysis tasks and documents you requested. See Microsoft’s documentation for more information on these advanced cases.
Once you have the AnalyzeActionsOperation you can work with its results.
Working with AnalyzeActionsOperation Results
The AnalyzeActionsOperation contains a Value property which is an AsyncPageable<AnalyzeActionsResult> object suitable for working with large volumes of results which may be returned asynchronously.
We can loop over this result with an async foreach to look at each “page” of our paged data. In our case there should only be a single page in the results, but if you’re analyzing many documents at once you may encounter multiple pages of results.
From there, we can look at the AnalyzeActionsResult object to see the results for each type of action we requested earlier.
The code for this can get overwhelming so I like to create a method for each type of analysis operation as shown here:
await foreach (AnalyzeActionsResult result in operation.Value)
{
foreach (AbstractiveSummarizeResult abstractResult in result.AbstractiveSummarizeResults.SelectMany(r => r.DocumentsResults))
{
DisplayAbstractiveSummaryResult(abstractResult);
}
foreach (ExtractiveSummarizeResult extractResult in result.ExtractiveSummarizeResults.SelectMany(r => r.DocumentsResults))
{
DisplayExtractiveSummaryResult(extractResult);
}
foreach (AnalyzeSentimentResult sentimentResult in result.AnalyzeSentimentResults.SelectMany(r => r.DocumentsResults))
{
DisplaySentimentAnalysisResult(sentimentResult.DocumentSentiment);
}
foreach (ExtractKeyPhrasesResult keyPhraseResult in result.ExtractKeyPhrasesResults.SelectMany(r => r.DocumentsResults))
{
DisplayKeyPhrasesResult(keyPhraseResult);
}
foreach (RecognizeEntitiesResult entityResult in result.RecognizeEntitiesResults.SelectMany(r => r.DocumentsResults))
{
DisplayEntitiesResult(entityResult);
}
foreach (RecognizeLinkedEntitiesResult linkedEntityResult in result.RecognizeLinkedEntitiesResults.SelectMany(r => r.DocumentsResults))
{
DisplayLinkedEntitiesResult(linkedEntityResult);
}
foreach (RecognizePiiEntitiesResult piiEntityResult in result.RecognizePiiEntitiesResults.SelectMany(r => r.DocumentsResults))
{
DisplayPiiEntitiesResult(piiEntityResult);
}
foreach (AnalyzeHealthcareEntitiesResult healthcareEntityResult in result.AnalyzeHealthcareEntitiesResults.SelectMany(r => r.DocumentsResults))
{
DisplayHealthcareEntitiesResult(healthcareEntityResult);
}
}
Notice that these nested foreach statements all flatten the resulting result collections via LINQ’s SelectMany method. This lets us avoid nesting foreach statements inside of other foreach statements more than we already are. However, it does make these lines long and harder to read.
Handling Errors
Before we go on to looking at these individual analysis components, let’s talk about proper error handling with the analysis call.
Calls to AnalyzeActionsAsync or its synchronous friend AnalyzeActions can fail. When these calls fail, you’ll typically get one of three exceptions thrown:
RequestFailedExceptionthe Azure service returned a non-success response. This most commonly happens when you use the wrong url or an invalid key.NotSupportedExceptionthis is thrown when you’re requesting an action that is not supported in your Azure region. You may need to create a new resource in a different data center or remove an action you were attempting.ArgumentOutOfRangeExceptionseems to be undocumented, but I’ve seen this thrown when performing extractive summarization on text that is too short for Azure’s needs. You need over 40 characters of text or so to avoid this.
Because of this, I tend to add a try / catch when working with the call and only add extractive summarization once a length threshold is crossed:
AnalyzeActionsOperation? operation = null;
try
{
TextAnalyticsActions actions = new()
{
AnalyzeSentimentActions = new List<AnalyzeSentimentAction>() { new() },
AbstractiveSummarizeActions = new List<AbstractiveSummarizeAction>() { new() },
ExtractKeyPhrasesActions = new List<ExtractKeyPhrasesAction>() { new() },
RecognizeEntitiesActions = new List<RecognizeEntitiesAction>() { new() },
RecognizeLinkedEntitiesActions = new List<RecognizeLinkedEntitiesAction>() { new() },
RecognizePiiEntitiesActions = new List<RecognizePiiEntitiesAction>() { new() },
AnalyzeHealthcareEntitiesActions = new List<AnalyzeHealthcareEntitiesAction>() { new() },
};
// We'll get an ArgumentOutOfRangeException if the text is too short
if (documentText.Length > 40)
{
actions.ExtractiveSummarizeActions = new List<ExtractiveSummarizeAction>() { new() };
}
string[] documents = [documentText];
operation = await _client.AnalyzeActionsAsync(WaitUntil.Completed, documents, actions);
}
catch (RequestFailedException ex)
{
switch (ex.Status)
{
case 401: // Unauthenticated
case 403: // Unauthorized
Console.WriteLine("Request failed due to authentication failure. Check your AI services key and endpoint.");
break;
case 429: // Too Many Requests
Console.WriteLine("Request failed due to throttling. Please try again later.");
break;
default:
Console.WriteLine($"Request failed with status code {ex.Status} and message: {ex.Message}");
break;
}
}
catch (NotSupportedException ex)
{
Console.WriteLine($"Text analysis failed. The requested actions may not be possible in your Azure region: {ex.Message}");
}
catch (ArgumentOutOfRangeException ex)
{
Console.WriteLine($"Text analysis failed. This can happen when the provided text is too short: {ex.Message}");
}
After the try / catch block I then check the operation for null and loop over the resulting pages as shown earlier:
if (operation is not null)
{
await foreach (AnalyzeActionsResult result in operation.Value)
{
// Omitted for brevity
}
}
I prefer to keep the try / catch narrowly scoped to the analysis work so that it is clear the logic exists for the AnalyzeActionsAsync call and to clearly differentiate my code to make the request and my code to interpret the results.
Speaking of interpreting the results, let’s see how to work with the resulting operations.
Interpreting Analysis Results
Each property nested inside the AnalyzeActionsOperation results is a separate class that inherits from the TextAnalyticsResult.
This approach has some key benefits. Since each result is a TextAnalyticsResult, they all share common properties including:
Idreferencing the document identifier. This will be 0 if you sent in strings, or the document Id if you passedTextDocumentInputobjects to the analyze call.HasErrorandErrorindicating if the operation succeeded and details if something went wrong.Statisticscontaining optional information about how the document was processed (if you set a property when making the call to analyze the data)
I typically ignore the Id when I am only analyzing one document at a time, but the property is helpful when doing bulk text analytics. However, I will always check HasError since it’s possible a multi-aspect text analytics call might produce errors on some actions while succeeding for others.
With these commonalities out of the way, let’s jump into the individual analysis results.
Sentiment Analysis
Sentiment analysis is an attempt to classify a text document as being largely positive, negative, neutral, or a mix of positive and negative.
This can be helpful if you are looking at customer comments or reviews for a specific product or service. This can also be helpful for trying to understand the overall behavior patterns of individual users. This could help online forum moderators identify users who are frequently critical to potentially keep a closer eye on for abusive behavior trends, for example.
When you work with sentiment analysis you look at the DocumentSentiment object and get an overall Sentiment that will be either Positive, Negative, Neutral, or Mixed. Additionally, you’ll get a Confidences property for Positive, Negative, and Neutral classifications. These confidences range from 0 to 1 with 1 being 100% confident.
Here’s some sample code that displays the sentiment:
private static void DisplaySentimentAnalysisResult(DocumentSentiment result)
{
// Identify the core values we care about
TextSentiment likelySentiment = result.Sentiment;
double positiveConfidence = result.ConfidenceScores.Positive;
double neutralConfidence = result.ConfidenceScores.Neutral;
double negativeConfidence = result.ConfidenceScores.Negative;
Console.WriteLine($"Overall sentiment: {likelySentiment}");
Console.WriteLine($"Confidence %'s: {positiveConfidence:P} positive, {neutralConfidence:P} neutral, {negativeConfidence:P} negative");
}
In the case of our passage from A Christmas Carol, Azure classifies the passage as having an overall sentiment of Mixed with a 42% probability that the sentiment is positive, 27% chance the sentiment is negative, and a 32% chance the passage is neutral.
I think overall, I’d personally classify the passage as neutral or slightly negative since it talks about death, hidden purposes, clues being missed, and the like. However, I don’t find Azure’s “mixed” classification too off base.
In my observations, I’ve seen documents get mixed classifications when their positive and negative confidences are near the middle.
Abstractive Summarization
Abstractive summarization is a fancy way of talking about generating a text description of the overall contents of a document.
Here’s the abstractive summary of our paragraph on Scrooge from A Christmas Carol:
Scrooge, a character in a story, is initially surprised by the significance of conversations seemingly trivial to him. However, he believes these conversations must have a hidden purpose, possibly related to his own life or future. He is unsure if the conversations have any connection to his old partner, Jacob, or anyone directly related to him. He resolves to record every word and sight he experiences, particularly observing his own shadow, in the hope that it will provide a clue to the puzzles he is facing.
This is a pretty reasonable summary of the paragraph we’ve seen before. Let’s see the code that extracted it:
private static void DisplayAbstractiveSummaryResult(AbstractiveSummarizeResult result)
{
if (result.HasError)
{
Console.WriteLine($"AbstractiveSummarize failed with error: {result.Error.Message}");
return;
}
StringBuilder sb = new();
foreach (AbstractiveSummary summary in result.Summaries)
{
sb.Append(summary.Text + " ");
}
Console.WriteLine(sb.ToString());
}
Here we’re looking at the Summaries property of our result and aggregating together the summaries of the text into a single string before displaying it to the console.
I like to think of abstractive summarization as the equivalent of pasting the text into a large language model (LLM) and asking it to summarize the text. The difference here is that you don’t have to deploy a LLM or pick which model should be used or how to structure your prompt; You just tell Azure AI Services that you want it to summarize text and it takes care of those details for you.
With abstractive summarization covered, let’s take a look at extractive summarization.
Extractive Summarization
The difference between extractive summarization and abstractive summarization is that abstractive summarization generates new text containing a summary while extractive summarization attempts to summarize the document by extracting key passages from the original document.
In our case, the following three sentences were chosen to summarize the full paragraph:
They could scarcely be supposed to have any bearing on the death of Jacob, his old partner, for that was Past, and this Ghost’s province was the Future.
But nothing doubting that to whomsoever they applied they had some latent moral for his own improvement, he resolved to treasure up every word he heard, and everything he saw;
For he had an expectation that the conduct of his future self would give him the clue he missed, and would render the solution of these riddles easy.
These selected sentences seem to capture the overall purpose and feel of the selected passage.
The code for getting this result is very similar to generating abstractive summaries, except we deal with the ExtractiveSummarySentence object in our foreach loop:
private static void DisplayExtractiveSummaryResult(ExtractiveSummarizeResult item)
{
if (item.HasError)
{
Console.WriteLine($"ExtractiveSummarize failed with error: {result.Error.Message}");
return;
}
StringBuilder sb = new();
foreach (ExtractiveSummarySentence sentence in item.Sentences)
{
sb.AppendLine($"> {sentence.Text}");
}
Console.WriteLine(sb.ToString());
}
I could see extractive summarization being useful if you wanted to identify candidates for “pull quotes” in an online article like this one to help readers identify key points while scanning by highlighting individual sentences.
Speaking of key phrases, let’s look at key phrase extraction.
Key Phrase Extraction
Key phrase extraction tries to identify small pieces of the overall document that represent the key ideas or focuses of the document. Unlike abstractive and extractive summarization, key phrase extraction is less about summarizing the overall document and is more about identifying the key drivers of the overall document.
We can identify key phrases with the following C# code:
private static void DisplayKeyPhrasesResult(ExtractKeyPhrasesResult keyPhraseResult)
{
if (keyPhraseResult.HasError)
{
Console.WriteLine($"KeyPhraseExtraction failed with error: {keyPhraseResult.Error.Message}");
return;
}
if (keyPhraseResult.KeyPhrases.Count == 0)
{
Console.WriteLine("No key phrases found.");
return;
}
Console.WriteLine($"Key Phrases: {string.Join(", ", keyPhraseResult.KeyPhrases)}");
}
In this case, the key phrases identified were:
- hidden purpose
- old partner
- latent moral
- future self
- Scrooge
- Spirit
- importance
- conversations
- bearing
- death
- Jacob
- Past
- Ghost
- province
- one
- improvement
- word
- everything
- shadow
- expectation
- conduct
- clue
- solution
- riddles
In this case I feel the list of key phrases is on the longer side for this paragraph and not as helpful. However, I’ve also seen this list of key phrases be incredibly relevant (particularly for non-fiction content), so I suspect the model is struggling a bit with Dickens' older writing style.
Entity Recognition
If key phrase extraction is about identifying the major driving factors in a document, entity recognition is about identifying the major nouns in a document.
In the case of A Christmas Carol, those entities are Scrooge, first, Jacob, partner, and one. Most of these make sense, but first seems to refer to “at first”, which I don’t believe should be categorized as an entity. However, the word one here is referring to one as in some person or entity.
I do feel a little sorry for Azure here because it’s trained to identify entities in modern writing, not the more classical writing style found in this timeless classic.
Nonetheless, it did a reasonable job with the text. Let’s see how the code works for this:
private static void DisplayEntitiesResult(RecognizeEntitiesResult entityResult)
{
if (entityResult.HasError)
{
Console.WriteLine($"RecognizeEntities failed with error: {entityResult.Error.Message}");
return;
}
if (entityResult.Entities.Count == 0)
{
Console.WriteLine("No entities found.");
return;
}
Console.WriteLine($"Entities: {string.Join(", ", entityResult.Entities.Select(e => e.Text))}")
}
This is very similar to our key phrase code earlier, but the objects we’re working with are slightly different.
Let’s move on to a similar form of entity recognition.
Linked Entity Recognition
Linked entity recognition is entity recognition plus relevant links. In other words, linked entity recognition scans the document for entities it can link to external sources of knowledge on.
In theory, these external sources of knowledge can be any publicly accessible trustworthy piece of content, such as a FreeCodeCamp, W3 Schools article, or article in a respected publication. In practice, these seem to always be Wikipedia links. However, this behavior may change in the future as more sources are integrated into the model.
The code for displaying linked entities is very similar to the code for entity recognition earlier, except the LinkedEntity class also has a Url property:
private static void DisplayLinkedEntitiesResult(RecognizeLinkedEntitiesResult entityResult)
{
if (entityResult.HasError)
{
Console.WriteLine($"RecognizeLinkedEntities failed with error: {entityResult.Error.Message}");
return;
}
if (entityResult.Entities.Count == 0)
{
Console.WriteLine("No linked entities found.");
return;
}
StringBuilder sb = new();
sb.AppendLine("Linked Entities");
foreach (LinkedEntity entity in entityResult.Entities)
{
sb.AppendLine($"{entity.Name}: {entity.Url}");
}
Console.WriteLine(sb.ToString());
}
In our case the entities detected were:
- Scrooge (1951 film): https://en.wikipedia.org/wiki/Scrooge_(1951_film)
- Jacob: https://en.wikipedia.org/wiki/Jacob
- Past: https://en.wikipedia.org/wiki/Past
- Ghost: https://en.wikipedia.org/wiki/Ghost
Here I’m going to have to award these results a 2.5 out of 4 for accuracy.
While it did link to external sources, and each source was somewhat reasonable, it made a few mistakes. Notably, the prediction confused Jacob Marley from the story, with the Jacob found in various religious texts. Additionally, Scrooge here referred to the character of Scrooge and not the 1951 film Scrooge or the 1988 film Scrooged. However, these films all referred to the same character, so this is a pretty close result.
It’s not uncommon to see mistakes like this when working with linked entity recognition, so I would only use it when working with specific scenarios such as interpreting text in travel guides.
Let’s move on to another specialized form of entity recognition.
PII Entity Recognition
Personally identifiable information (PII) entity recognition is built around trying to identify potentially sensitive pieces of information in text that should remain anonymized. For example, when working with product reviews, you don’t want to see phone numbers, email addresses, or other sensitive pieces of information.
PII entity recognition will identify these pieces of information, give you a confidence level on its prediction, and also give you the category of the type of entity something is. This category can be potentially helpful if you only want to redact certain types of PII in your documents.
Our text has three PII entities: Scrooge, Jacob, and partner. Scrooge and Jacob are flagged correctly as Person entities with 100% confidence while partner is flagged as a PersonType with 79% confidence.
Azure also provides the offset of each string within the document text in case you wanted to perform string operations to redact the text to hide these entities.
The code for looking at PII results follows:
private static void DisplayPiiEntitiesResult(RecognizePiiEntitiesResult piiEntityResult)
{
if (piiEntityResult.HasError)
{
Console.WriteLine($"PII failed with error: {piiEntityResult.Error.Message}");
return;
}
if (piiEntityResult.Entities.Count == 0)
{
Console.WriteLine("No PII entities found.");
return;
}
StringBuilder sb = new();
foreach (PiiEntity entity in piiEntityResult.Entities.DistinctBy(e => e.Text))
{
string categoryName = entity.Category.ToString();
if (entity.SubCategory is not null)
{
categoryName += $"/{entity.SubCategory}";
}
sb.AppendLine($"{entity.Text}in category {categoryName} with {entity.ConfidenceScore:P} confidence (offset {entity.Offset})");
}
Console.WriteLine(sb.ToString());
}
Let’s look at our last form of entity recognition we’ll cover.
Healthcare Entity Recognition
Microsoft is committed to supporting medical AI scenarios on Azure. To that end, they’ve provided healthcare entity recognition as a specific form of text analysis on Azure.
Healthcare entity recognition is specifically built to detect information related to the treatment of patients and can be used for analyzing patient records and treatment notes.
Like PII entity recognition, healthcare entity recognition tells us the category of each entity as well as its confidence and offset, however the results are much more healthcare specific.
The code for this should be somewhat familiar:
private static void DisplayHealthcareEntitiesResult(AnalyzeHealthcareEntitiesResult healthcareEntityResult)
{
if (healthcareEntityResult.HasError)
{
Console.WriteLine($"HealthCare Entities failed with error: {healthcareEntityResult.Error.Message}");
return;
}
if (healthcareEntityResult.Entities.Count == 0)
{
Console.WriteLine("No healthcare entities found.");
return;
}
StringBuilder sb = new();
foreach (HealthcareEntity entity in healthcareEntityResult.Entities.DistinctBy(e => e.Text))
{
sb.AppendLine($"{entity.Text}: in category {entity.Category} with {entity.ConfidenceScore:P} confidence (offset {entity.Offset})");
}
Console.WriteLine(sb.ToString());
}
Although our passage isn’t related to healthcare, healthcare entity recognition does a remarkable job with it and flags death as a Diagnosis with 82% confidence and partner as a FamilyRelation at 88% confidence. Both of these results are plausible and I can’t fault Azure for these results.
Healthcare entity recognition performs much more poorly against non-healthcare related text. For example, in one early experiment it flagged the CodeMash conference as a form of medication (which is somewhat accurate as I find it very energizing). However, in the right scenarios, healthcare entity recognition could be very helpful in quickly indexing medical records for later search or analysis.
Summary and Next Steps
This concludes our tour of using Azure AI Language services to perform bulk analysis of either a single document or multiple text documents with a single API call.
While the code isn’t always as simple as I wish it was, I’m very pleased with how effective Microsoft has made their Azure AI capabilities for natural language processing tasks.
Believe it or not, I’ve actually not covered all of the major types of actions possible using Azure AI Language. Using this same API, it’s also possible to perform single label classification, multi-label classification, and performing entity recognition using a custom model. However, each one of these tasks is more complex and would need an article all on its own to cover its usage.
Hopefully I have convinced you of the flexibility and power of Azure’s text analytics APIs. These capabilities are often one of the first things I turn to when I want to add some form of additional intelligence to an application, when I need help identifying certain types of PII, or simply when I want to summarize larger pieces of text in a concise manner.
Give these APIs a try and let me know what you think.

